LR face landmark
采用鲁棒显著性人脸地标检测实现高效灵活的人脸图像去模糊Towards more efficient and flexible face image deblurring using robust salient face landmark detection
Huang, Y., Yao, H., Zhao, S. et al. Towards more efficient and flexible face image deblurring using robust salient face landmark detection. Multimed Tools Appl 76, 123–142 (2017). https://doi.org/10.1007/s11042-015-3009-3
Yinghao Huang1·Hongxun Yao1·Sicheng Zhao1·Yanhao Zhang1
School of Computer Science and Technology, Harbin Institute of Technology
评价:将经典的$L_0$去模糊方法与人脸地标检测相结合实现高效灵活的人脸图像去模糊。
针对问题:人脸图像的去模糊。
本文的目的:更好地处理各种复杂的人脸姿态、形状和表情,同时大大减少了计算时间。(基于样本数据集的人脸图像去模糊方法的问题会出现即使是最好的候选图像也不能很好地匹配输入图像)
实现的方法:地标探测器被用来检测主要的面部轮廓,然后将检测到的轮廓作为显著边缘引导盲图像去卷积。
方法的框架如图2所示,主要由三个部分组成:
(1)鲁棒人脸地标检测器训练;
(2)显著轮廓检测和。
(3)盲图像去模糊。
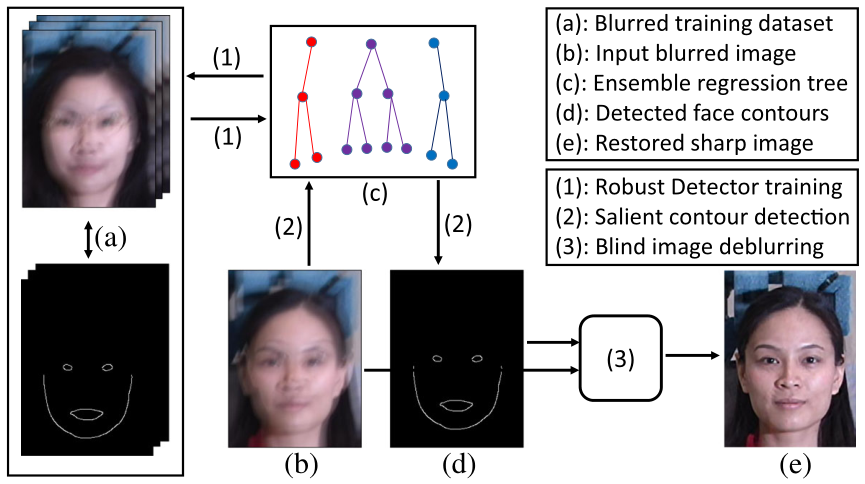
方法的框架。这里,数字(1-3)和字母(a-e)分别表示操作和实体。如图所示,整个算法可以分为三个步骤:(1)鲁棒检测器训练,(2)显著轮廓检测,(3)盲图像去模糊。在检测器训练阶段(1),根据大的训练数据集(a)构造回归森林集合,得到回归森林集合,这是几个广泛使用的人脸地标检测数据集的模糊版本。在测试阶段,给定一个模糊的图像(b),首先应用训练凸轮廓探测器得到凸边,如(2)所示。然后估计凸轮廓的帮助下,实现大幅面图像通过盲图像去模糊(3)。
利用检测到的显著面部轮廓尽可能准确地估计模糊核,之后恢复潜在图像,采用共轭梯度法求解。
The 3D Menpo Facial Landmark Tracking Challenge
2017 IEEE International Conference on Computer Vision Workshops (ICCVW)
Stefanos Zafeiriou∗,1,2Grigorios G. Chrysos∗,1Anastasios Roussos∗,1,3 Evangelos V erveras1Jiankang Deng1 George Trigeorgis1
1Department of Computing, Imperial College London, UK
2Center for Machine Vision and Signal Analysis, University of Oulu, Finland
3Department of Computer Science, University of Exeter, UK引用量235
评价:
提供了一个包含3DA -2D和3D面部地标的大规模面部图像数据库。
提出了一个复杂的程序来估计任意“野外”视频中的3DA - 2D和3D地标。该程序是高度准确的,并用于提供超过28万注释帧。
我们给出了3DA - 2D和3D地标跟踪的第一个挑战的结果。
针对问题:所提供的2D标注很少捕捉到面部的3D结构(这在面部边界上尤其明显)。也就是说,注释既不提供深度估计,也不对应于三维面部结构的2D投影。
2D数据集许多地标几乎不对应于人脸的3D结构。也就是说,它们不能准确地对应于三维面部结构的任何地标在图像平面上的投影。此外,上述基准的2D注释不包含关于3D面深度的任何信息。在本文中,我们将图像平面上的三维地标的二维投影称为3DA -2D地标,以区别于三维场景中面部地标的三维坐标。

侧脸情况下隐藏的半边脸的标注是另一边脸的轮廓。
https://ibug.doc.ic.ac.uk/resources/1st-3d-face-tracking-wild-competition/
用此数据集训练脸?问题在于它的标注是估计出来的,无法保证精确性。
RGB-D-based gaze point estimation via multi-column CNNs and facial landmarks global optimization
Zhang, Z., Lian, D. & Gao, S. RGB-D-based gaze point estimation via multi-column CNNs and facial landmarks global optimization. Vis Comput 37, 1731–1741 (2021). https://doi.org/10.1007/s00371-020-01934-1
评价:基于rgb - d的多列cnn和人脸地标全局优化的注视点估计。利用一个多列multi-column cnn框架,从一个人的RGB-D图像来估计坐在显示器前的人的注视点。
针对问题:捕获的深度图像通常包含噪声和黑洞,阻碍我们获得可靠的头部姿态和3D眼睛位置估计。
实现的方法:视点由头部姿态、眼球姿态和眼睛三维位置决定。推断这三个分量,然后将它们整合来估计注视点。
从RGB人脸图像中估计出68个人脸关键点的相对深度,然后利用这些相对深度和捕获的原始深度([40]),通过全局优化求解所有人脸关键点的绝对深度。精确的深度提供可靠的头部姿态和3D眼睛位置的估计。
眼球姿势,通过多列CNN得到;
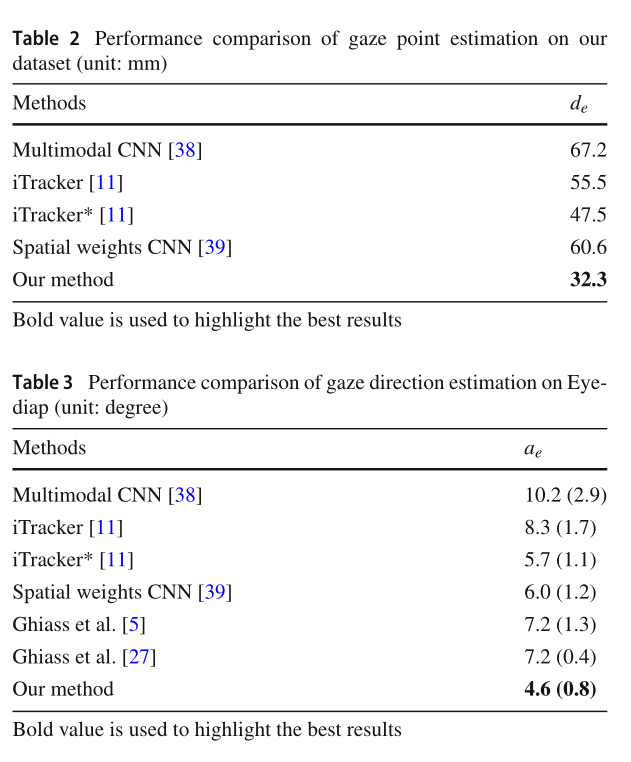
头部姿势和眼睛位置通过两步程序从RGB和深度图像中估计68个3D面部地标(见图4)来解决的。
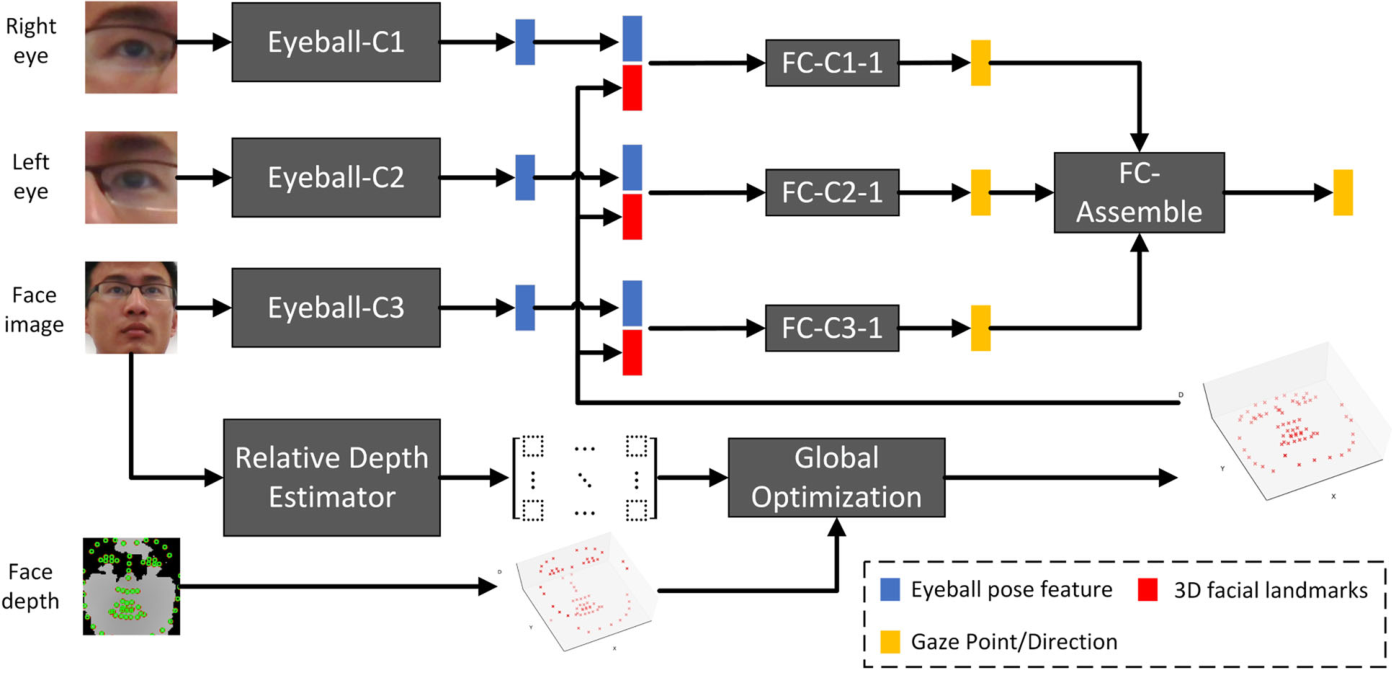
我们的注视点估计框架。使用三个独立的特征提取器(即Eyeball- c1、Eyeball- c2和Eyeball- c3,在我们的实现中这三个独立的ResNet-18)从两张单眼图像和人脸图像中提取眼球姿态特征。人脸标志物的相对深度是由相对深度估计器(另一种ResNet-18)从人脸图像中估计出来的。然后,利用估计的相对深度和原始深度,通过全局优化获得可靠的三维面部地标。三个CNN列提取的眼球构成特性和最优的三维面部地标被送入三套完全连接层(即FC-C1-1、FC-C2-1 FC-C3-1图,在我们的实现中,每个层都由两个级联的完全连接的层组成))为注视点回归。最后,由最后一个完全连接层收集来自CNN三个栏目的三个独立的凝视预测,进行最终预测。
采用了与[40]相似的策略,其中使用RGB图像来预测面部地标对的相对深度,并通过使用估计的相对深度和原始深度进行全局优化获得绝对深度。
看一下关键点是怎么得出的?使用了dlib toolkit。
数据收集方法
每个参与者都被要求坐下在27英寸的iMac前,电脑安装了英特尔RealSense SR300摄像头,距离从50厘米到100厘米不等,当参与者准备好了,他或她可以在我们的数据收集软件中输入他或她的名字,并开始一个收集会话。在每个实验中,随机出现50个半径为30像素的白点(在1920×1080像素分辨率下约为0.93 cm),参与者被要求依次点击白点的中心。同时,数据采集软件记录每个白点的位置,每次点击的位置,以及参与者的RGB-D图像。在一个会话结束后,参与者可以在开始下一个会话之前短暂休息,直到全部16个会话结束。
在数据收集过程中,我们假设参与者应该盯着中间的白点。然而,这并不总是正确的,特别是当参与者在点击点时分心。为了避免这种情况,我们还用蓝点向参与者展示了每次点击的位置。此外,我们通过测量白点中心和点击位置之间的距离来确定样品。如果距离比给定的阈值(10个像素0.31cm 1920×1080像素))更远,我们就简单地从数据集中排除该样本。训练集包含159个参与者的119,318个样本,验证集包含其余59个参与者的45,913个样本。

没有固定参与者和显示器之间的距离,也没有固定左右的深度,每个参与者的眼睛变化幅度很大,超过一半的参与者在实验中佩戴了眼镜,这使得他们的深度图像中眼睛区域包含了大的黑洞。
2019AAAI RGBD Based Gaze Estimation via Multi-task CNN
消融实验
为了探索不同凝视跟踪模块的有效性,我们报告了从网络中移除不同组件后的性能。我们在我们的数据集和Eyedip数据集上进行了这些实验。表4列出了所有基线方法的结果。
对于注视点估计,我们的网络结合了头部姿势特征、眼球姿势特征和3D眼睛位置特征。
对于凝视方向估计,我们只连接头部姿势特征和眼球姿势特征。

首先,我们删除头部姿势信息,这意味着网络只需要两个单眼睛图像和3D眼睛位置作为输入,这导致记录的性能最差。如前所述,头部姿势对于凝视估计是必要的,否则,网络将过拟合。RGB图像和深度贴图都提供头部姿势信息。接下来,我们分别移除RGB图像和深度贴图。与移除RGB输入相比,移除深度输入可以获得更好的性能,这表明RGB人脸数据比人脸深度数据具有更好的表现力。
还值得注意的是,no depth去除深度和iTracker*(Krafka et al.2016)之间的区别在于3D眼睛位置编码方法。要获取3D眼睛位置信息,二值化图(称为面部网格)用于指示图像中的面部区域,而面部的大小及其在相机捕获的图像中的位置粗略地编码了3D眼睛坐标。如表4所示,我们精确的3D眼睛位置略微提高了性能(46.7毫米对47.5毫米)。
此外,我们还在深度重建过程中移除了解码模块,获得了比深度重建更差的性能,这验证了深度细化在我们的网络中的有效性。由于深度重建的监督,该网络可以更好地学习头部姿势特征的表示。最后,由于我们引入了深度图来提取头部姿势特征,我们还进行了RGB图像与深度图相结合的实验。我们将两者叠加在一起以提取头部姿势特征,并将其表示为叠加RGB深度,但这会导致性能比我们的方法差。
Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment
CVPR2018
Amit Kumar Rama Chellappa
Department of Electrical and Computer Engineering, CFAR and UMIACS
University of Maryland-College Park,USA
评价:在树突状CNN中解纠缠3D姿态用于无约束2D人脸对齐,提出了姿态条件树突卷积神经网络Pose Conditioned Dendritic Convolution Neural Network (PCD-CNN);它使用单个CNN来模拟面部地标的树突结构。
针对问题:利用贝叶斯框架对头部姿态进行解缠,对不同的姿态的地标估计来分解人脸图像的3D姿态,使其与人脸姿态无关,从而减少了定位误差。


提出的方法的细节。卷积层顶部的虚线表示残差连接。树突关键点网是基于PoseNet的。灰色盒子内的网络代表了建议的PCD-CNN,而蓝色盒子内的第二个网络是模块化的,可以用于辅助任务。与这些辅助网络一起使用的是用于更精细定位的卷积-反卷积网络。
提出了人脸标志点的树突结构,实现了标志点之间的有效信息共享。树状结构的节点是反卷积的输出,而节点与节点之间的边缘采用卷积函数(fij)建模。反卷积网络结构如图3所示。
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
2017ICCV
Adrian Bulat and Georgios Tzimiropoulos
Computer Vision Laboratory, The University of Nottingham
Nottingham, United Kingdom
LS3D-W