遇到的问题
1.ImportError: cannot import name ‘DtypeArg’ from ‘pandas._typing’
ImportError:无法从’pandas导入名称“DtypeArg” - 我爱学习网 (5axxw.com)
使用pip list查看
卸载重装即可。
2. File “/home/workspace/feifeizhang/anconda/lib/python3.7/site-packages/pandas/core/indexes/base.py”, line 3363, in get_loc raise KeyError(key) from err KeyError: ‘left_eye_coord’
1 | self.le_coord_list = (root_dir + "/" + self.anno["left_eye_coord"]).tolist() |
源代码中这两行被注释掉了,但是如果注释掉会出现
le_coor = np.load(self.le_coord_list[idx])
AttributeError: ‘GazePointAllDataset’ object has no attribute ‘le_coord_list’
解决办法
已经发现了数据组织结构的问题。看代码gaze_dataset.py发现数据组织格式有问题,运行GAZE/RG-BD-Gaze-master/code/data/data_check.py有
Traceback (most recent call last):
File “/home/workspace/feifeizhang/GAZE/RGBD-Gaze-master/code/data/data_check.py”, line 1, in
from data.gaze_dataset import GazePointAllDataset
ModuleNotFoundError: No module named ‘data’看一下cord的.npy文件,读出来。或者发邮件吧。
3.RuntimeError: expand(torch.cuda.FloatTensor{[2, 1]}, size=[]): the number of sizes provided (0) must be greater or equal to the number of dimensions in the tensor (2)
Traceback (most recent call last):
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 666, in
trainer.train_base(epochs= total_epochs, lr=learning_rate,use_refined_depth=True)
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 118, in train_base
self._train_base_epoch()
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 411, in _train_base_epoch
left_eye_info[j, 2] = th.median(cur_depth).item() * face_factor
RuntimeError: expand(torch.cuda.FloatTensor{[2, 1]}, size=[]): the number of sizes provided (0) must be greater or equal to the number of dimensions in the tensor (2)
非常奇怪的是,当我把batchsize设置为1时,此问题消失了orz
1 | if self.temps.use_refined_depth: |
1 | #打印出维度,查看结果 |
the shape of depth: torch.Size([1, 88, 88])
the shape of left_eye_info : torch.Size([16, 3])
left_eye_info[j, 2] tensor(0.9088, device=’cuda:0’)
median depth: tensor([[0.6016],
[0.6016],
[0.5006],
[0.5006],
[0.6016],
[0.6016],
[0.5006],
[0.5025],
[0.5006],
[0.4179],
[0.4179],
[0.5025],
[0.3485],
[0.5006],
[0.4179],
[0.5025]], device=’cuda:0’)
median shape torch.Size([16, 1])
Traceback (most recent call last):
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 676, in
trainer.train_base(epochs= total_epochs, lr=learning_rate,use_refined_depth=True)
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 119, in train_base
self._train_base_epoch()
File “/home/workspace/feifeizhang/RGBDgaze/RGBD-Gaze-master/code/trainer_aaai.py”, line 419, in _train_base_epoch
left_eye_info[j, 2] = th.mean(a).item() * face_factor
RuntimeError: expand(torch.cuda.FloatTensor{[16, 1]}, size=[]): the number of sizes provided (0) must be greater or equal to the number of dimensions in the tensor (2)
找到原因啦!其实是face_factor是这个batch的face_factor
程序结构
目录
gen landmark.py
trainer_aaai.py
1 | class GazeTrainer(Trainer): |
在调用GazeTrainer类后会继承父类Trainer,父类位于文件下GAZE/RGBD-Gaze-master/code/utils/trainer.py
1 | def __init__(self, checkpoint_dir='./', is_cuda=True):#初始化 |
GAZE/RGBD-Gaze-master/code/utils/edict.py
1 | #对于字典的编辑 |
gaze_aaai.py
1 | def resnet34(pretrained=False, **kwargs): |
down层输入为1024,感觉是两个512的feature级联起来的。
1 | def forward(self, face, depth): |
GAZE/RGBD-Gaze-master/code/data/gaze_dataset.py
27英寸,长60厘米,宽34厘米(精确值:59.77厘米,33.62厘米)
在trainer_aaai.py调用时候
1 | transformed_train_dataset = GazePointAllDataset(root_dir=self.data_root,transform=data_transforms['train'],phase='train',face_image=True, face_depth=True, eye_image=True,eye_depth=True,info=True, eye_bbox=True, face_bbox=True, eye_coord=True) |
1 | class GazePointAllDataset(data.Dataset): |
程序错误:数据集train_csv没有left_eye_coord、lift_eye_coord,感觉是这个类调用有问题,或者是类的构造有问题。导致加载数据出错。
数据集结构
数据集由165231个RGB/depth图像对组成。使用159个参与者对应的图像(119,318个RGB/depth图像对)作为训练数据,使用其余59个参与者对应的数据(45,913个RGB/depth图像对)作为测试数据。
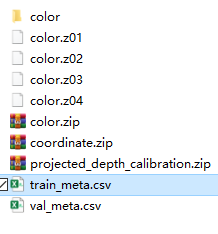
tran_meta.csv包含了119,318个RGB/depth图像对,表头有12项,分别为
A.图片index。
B.face_images图片存的位置,位于color文件夹下。
C.face_depth存的位置,位于projected_depth_calibration。
D.face_bbox,存于txt文件中,为4个坐标值,位于color文件夹下。
E.left_eye_image,位于color文件夹下。
F.right_eye_image,位于color文件夹下。
G.left_eye_depth,位于projected_depth_calibration下。
H.right_eye_depth,位于projected_depth_calibration下。
I.left_eye_bbox,位于color文件夹下。
J.right_eye_bbox,位于color文件夹下。
K.gaze_point,位于coordinate文件夹下,文件名以.npy结尾,文件中储存的是坐标。
L.has_landmark,值为TRUE或者FALSE,大部分值都为TRUE。
color、projected_depth_calibration、coordinate文件夹均有219个文件夹对应219个志愿者,每个志愿者的文件夹下有多组实验的数据。
color文件夹下存放了219个志愿者的rgb相关信息,一组实验包含7个信息,全脸、左右眼的图片以及bbox,还有人脸的68点landmark。
projected_depth_calibration文件夹下存放了219个志愿者的depth相关信息,一组实验包含3个信息,分别为左右眼和全脸depth。
coordinate文件夹下存放了219个志愿者眼睛坐标系。
少了 le 坐标系,r坐标系。不知道如果这俩怎么在网络中使用?如果拿掉会怎么样。.mat格式里边是不是保存有?python转换一个,mat文件至excel看一下格式吧
读取数据集遇到的问题
企图通过各个特征维度来获得 le cord 和ri cord是啥?/(ㄒoㄒ)/~~

resnet 34返回特征 512维度。(经过pooling,每个维度只有一个点)
1 | def forward(self, face, depth): |
似乎找到问题的答案啦!
1 | #train_aaai.py |
使用眼边缘六个点做平均获得眼睛中心位置。
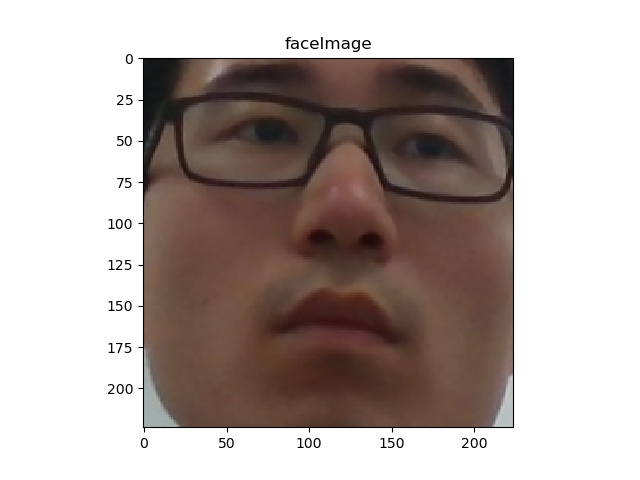
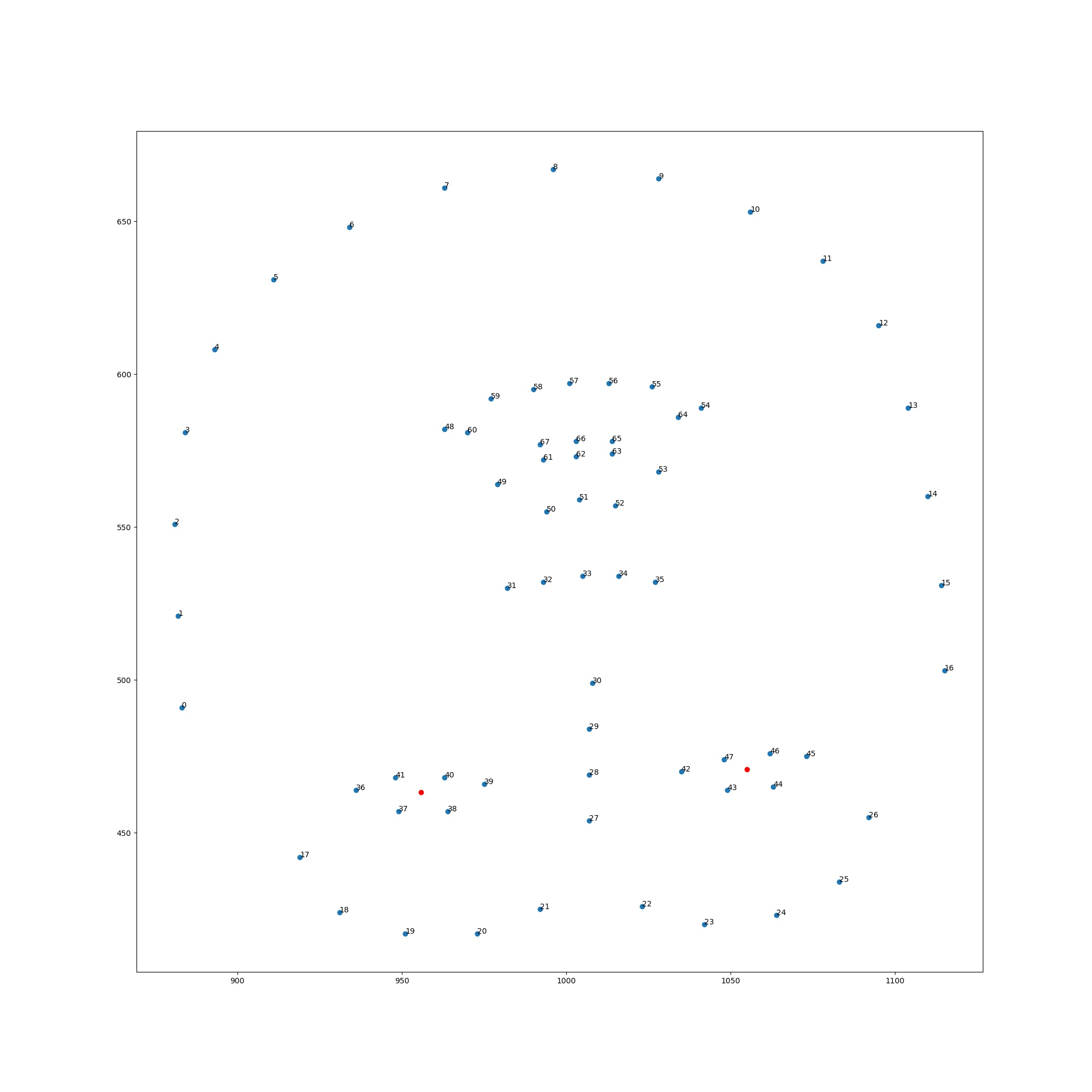
屏幕分辨率1080(540),1960(980)。对于一个图片矩阵,(0,0)在左上,所以这里显示的landmark图片是upside down的。
处理
读出保存数据的csv,计算landmark眼周六点的平均值,获得双眼中心,保存至csv。对于landmark不存在的数据,从保存数据的csv中删除。
测试集没有删除数据,训练集合数据从119317删除至98629。
程序中对于gt处理,为什么有一个screen/2平移
w_screen=59.77, h_screen=33.62
gt[0] -= self.w_screen / 2
gt[1] -= self.h_screen / 2
为什么程序有一个减法?相当于平移。




上海科大的深度图的动态范围是啥?太黑了。
用了numpy和opencv读全都是黑乎乎的。
/home/workspace/feifeizhang/GAZE/RGBD-Gaze-master/SHtechSave/results/gaze_aaai_refine_headpose/val/depth
 ep00iter0000_rf.png
ep00iter0000_rf.png
看一下怎么保存的吧。动态范围