2018 TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
Dongze Lian, Lina Hu, Weixin Luo, Y anyu Xu, Lixin Duan, Jingyi Y u,Member , IEEE, and Shenghua Gao.
(1) 评价:基于深度卷积神经网络的多视图多任务注视估计
(2) 针对问题:现有的许多方法都是基于单个摄像机的,大多数方法只关注注视点估计或注视方向估计。
(3) 本文的方法:
a.分析了注视点估计和注视方向估计之间的密切关系,并采用部分共享卷积神经网络结构来同时估计注视方向和注视点。
b.引入了一种新的多视角注视跟踪数据集,该数据集由不同被试的多视角注视图像组成。
c.对于注视方向的预测,提出在左右眼注视方向上引入共面约束。
对于注视点的估计,提出引入一个跨视图池模块。
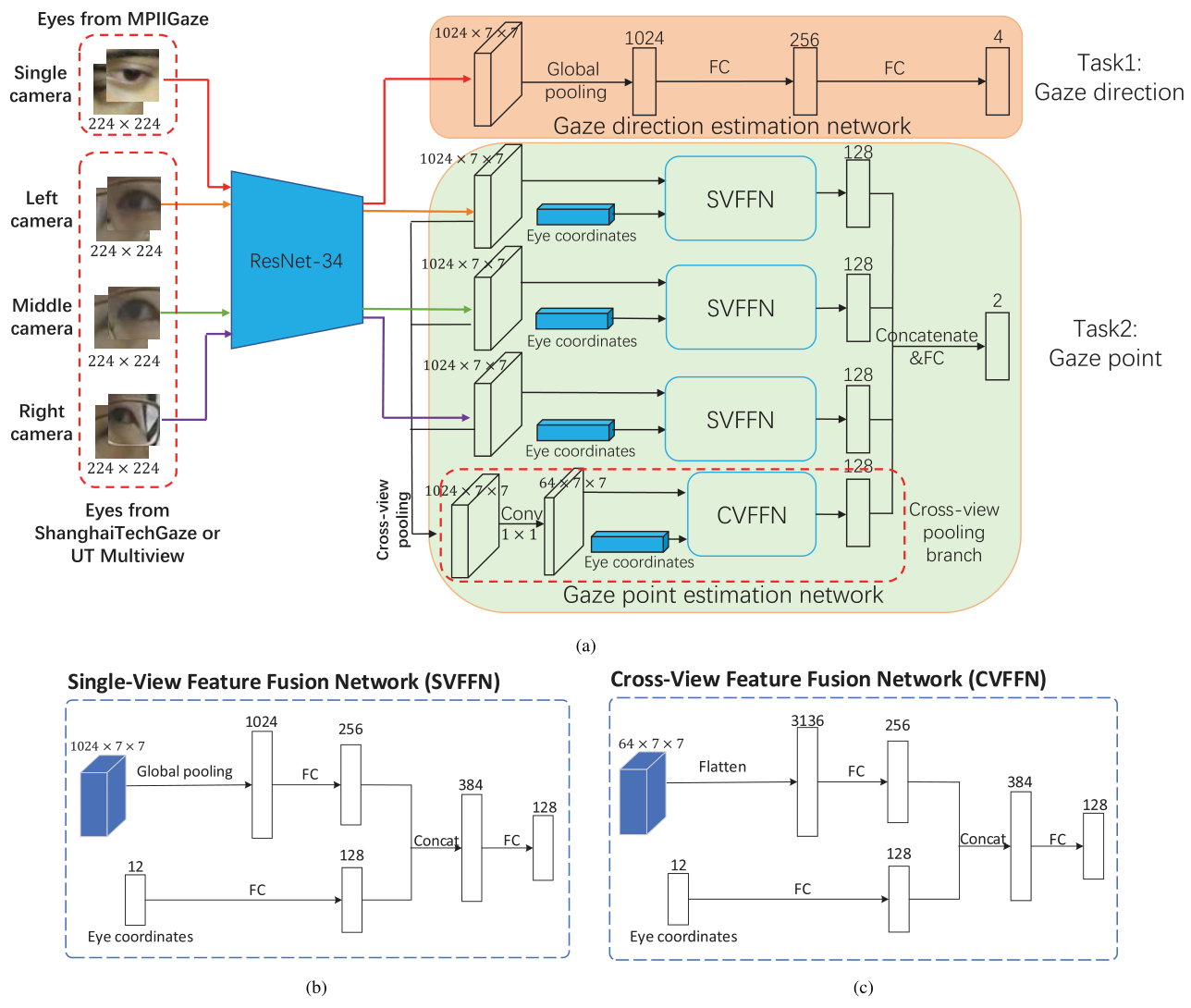
四流输入、四流输出?怎么共享参数?
https://datasets.d2.mpi-inf.mpg.de/MPIIGaze/MPIIGaze.tar.gz
使用多视角相对于单视角的好处:
对于基于外观的凝视跟踪,许多以前的工作[5]、[7]试图使用单视图相机收集数据。它们中的大多数要么固定头部姿势,要么忽略不同对象眼睛与屏幕目标之间的深度信息。如图1所示,眼睛在三维坐标系中的位置O和凝视方向$g_l=(x,y,z)$都决定了凝视点在二维平面中的位置$g_p=(x_p,y_p)$。
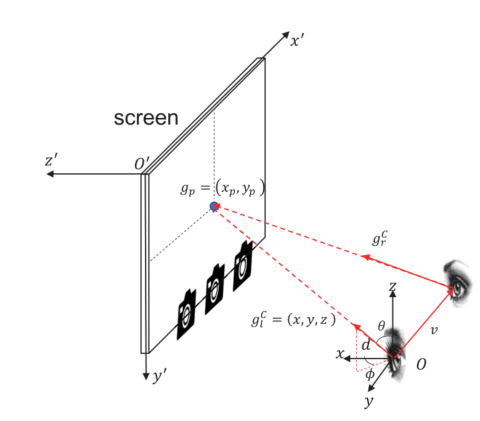
注视点位置取决于注视方向和眼睛位置。O是眼睛在三维坐标系中的位置,$g_l^C$、$g_r^C$是左眼和右眼的注视方向,$g_p$是二维注视点,$v$是从左眼到右眼的向量
在相同的注视方向下,即使眼睛的轻微深度变化也很容易导致较大的估计偏差。然而,单视图相机无法很好地估计眼睛的深度。因此,在大多数单视图凝视跟踪系统中,受试者必须调整头部姿势,以确保他们的眼睛能被相机捕捉并确定深度。然而,这样的限制会损害用户体验。
幸运的是,眼睛和屏幕之间的深度可以从多视图图像中推断出来。
1.因此,我们建议利用多视点相机捕捉的图像进行更好的视线跟踪,这样的多视点相机系统间接地引入了深度信息进行视线跟踪。
2.之前的工作[8],[9]已经表明,多视图学习将利用来自不同视图的数据来学习更健壮的表示,具有更好的泛化能力。在凝视跟踪应用中,与基于单视图的凝视跟踪相比,多视图相机放松了对参与者头部姿势的约束。
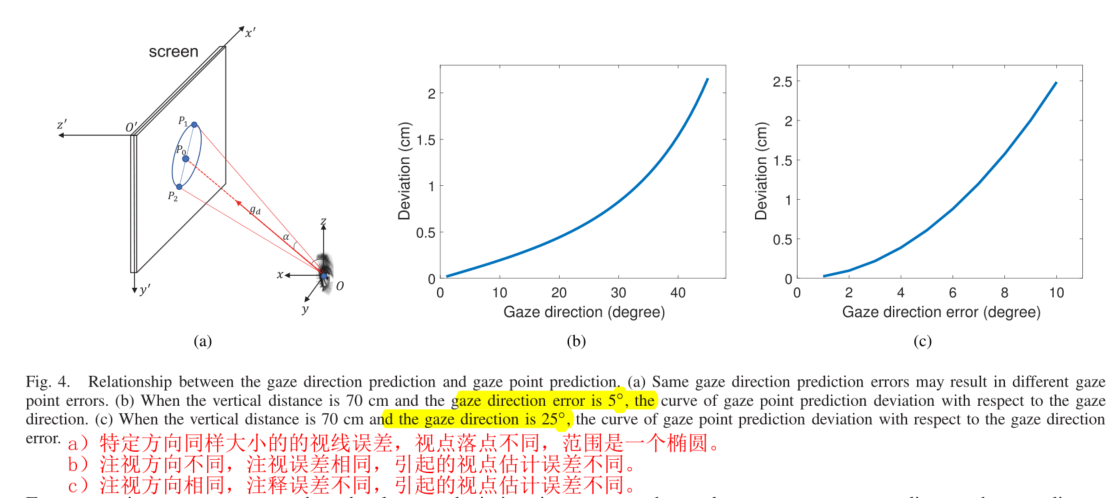
数据集ShanghaiTechGaze
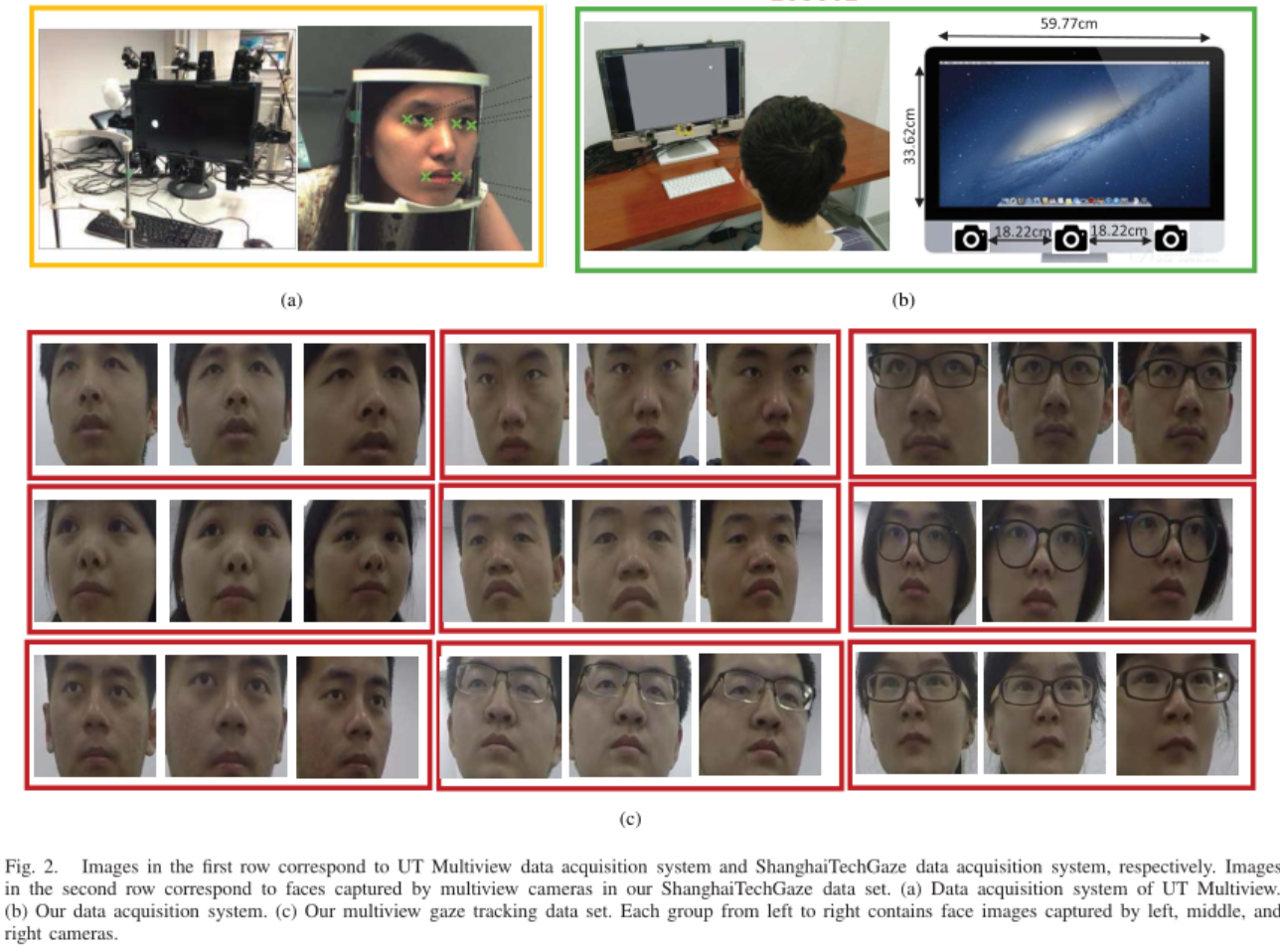
设备:使用27英寸的苹果iMac机器作为显示设备。屏幕的宽/高分别为59.77厘米和33.62厘米。然后,屏幕底部部署了三台GoPro Hero 4相机,以捕捉参与者的图像。两台相邻摄像机之间的距离为18.22厘米。
环境:然后,在正常照明条件下,将系统固定在房间的书桌上。为了避免其他移动的物体/人或噪音造成的干扰,房间内保持安静和空无一人,只有一名待命助手除外。
使用大型iMac的第一个原因是,希望在水平和垂直方向上预测更大范围的注视点。相比之下,GazeCapture只预测了手机或平板电脑屏幕内的点。因此,数据集比GazeCapture更具挑战性。
使用iMac的第二个原因是,它的视网膜屏幕有更高的分辨率,以保证像素精度的地面真实;同时,减少了数据采集过程中的眼睛疲劳。
采集过程:要求参与者自由地坐在屏幕前。然后,在灰色背景的屏幕上随机显示一个半径为8像素的白点(作为ground truth),让参与者用鼠标点击。这样的点击动作可以帮助参与者将注意力吸引到这个点上。然后,记录光标的坐标和动作的时间戳,之后显示光标位置上的蓝点。同时,我们计算白点和蓝点之间的距离。如果距离超过一定的阈值(在我们的设置中是8像素),则有可能参与者没有盯着白点,因此该数据样本将被丢弃。在采集过程中,GoPro相机被设置为视频模式。根据点击动作的时间戳,我们可以从视频中提取参与者的图像帧。对于每个参与者,在记录数据之前,要求他/她先点击9个点,熟悉数据采集系统。接下来,50个点将在每个环节依次显示给参与者,以进行数据采集。当参与者成功点击上一个点后,屏幕会闪烁,下一个点会显示出来。每个参与者被要求点击12期(总共点击600个点)。在两个周期之间,我们设置了1分钟的休息时间,以避免眼睛疲劳。
我们总共招募了137名学生参与者进行数据收集(年龄在20 — 24岁之间,男性98名,女性39名)。所有参与者视力正常或矫正至正常。在去除白点与蓝点之间距离大于阈值的数据样本后,为每个参与者保留约450-600个点及其对应的眼睛和面孔图像。最后ShanghaiTechGaze数据集由233 796张图像组成。我们进一步使用100个参与者对应的图像作为训练集,其余37个参与者对应的图像作为测试集。
数据组织格式
—|dataset
——|annotations
———|txtfile
————|test_txt
—————|leftcamera
——————|eyelocation.txt (images/face_landmarks/leftcamera/00109/00000.mat-images/face_landmarks/leftcamera/00147/00599.mat)21301rows
——————|lefteye.txt (images/Single_eyes/leftcamera/00109/00000_left.jpg-images/Single_eyes/leftcamera/00147/00599_left.jpg)
——————|righteye.txt (images/Single_eyes/leftcamera/00109/00000_right.jpg)
—————|middlecamera
——————|eyelocation.txt
——————|lefteye.txt
——————|righteye.txt
—————|rightcamera
——————|eyelocation.txt
——————|lefteye.txt
——————|righteye.txt
—————|gt.txt (images/coordinate/00109/00000.mat-images/coordinate/00147/00599.mat)
————|train_txt
(images/coordinate/00004/00000.mat-images/coordinate/00108/00599.mat)56631rows
——|images
———|coordinate
————|candidate_index
—————|00000.mat-00599.mat 存放2维数据,真值。
———|face_landmarks(eyelocation,candidate_index,00000.mat-00599.mat)
————|leftcamera存放24维数据
————|middlecamera
————|rightcamera
———|Single_eyes(eye_patch,candidate_index,00000_left.jpg-00599_left.jpg,00000_right.jpg-00599_right.jpg)
————|leftcamera
————|middlecamera
————|rightcamera
眼睛的landmart位置信息和gt使用.mat格式存储。
实验code
查看mat格式。能不能清晰的读出来,是否需要下载matlab?
dataloader的getitem函数在enumerate部分
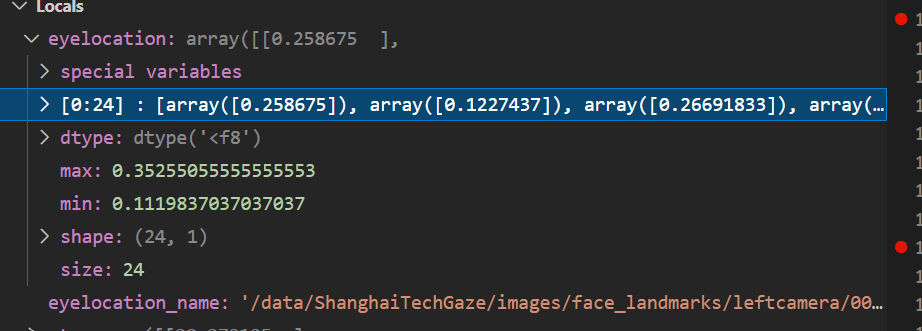
123行 eyelocation = sio.loadmat(eyelocation_name)[‘eyelocation’]是个24个数字
eyelocation_name = ’/data/ShanghaiTechGaze/images/face_landmarks/leftcamera/00061/00157.mat’
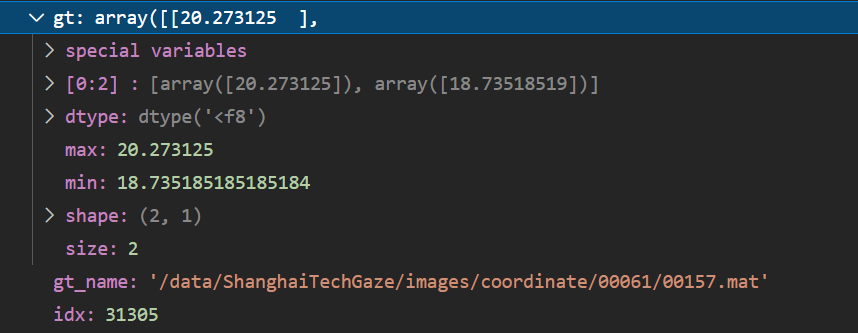
124行gt = sio.loadmat(gt_name)[‘xy_gt’]是两个数字
gt_name = ‘/data/ShanghaiTechGaze/images/coordinate/00061/00157.mat’
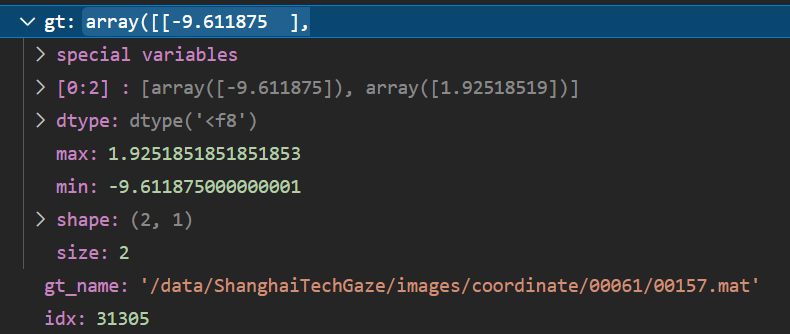
数据Normalization 是因为是左眼吗所以这么处理。
gt[0] -= W_screen / 2 宽
gt[1] -= H_screen / 2 高
第151行 data, target = (input[‘le’], input[‘re’], input[‘eyelocation’]), input[‘gt’]
multi-view-gaze-master/code/Train_Single_View_ST.py
1 | class GazeImageDataset(Dataset): |
1 | def train(train_loader, model, criterion, optimizer, epoch): |
1 | class AverageMeter(object): |
1 | def compute_error(output, target): |
multi-view-gaze-master/code/network/gazenet.py
1 | #选对应的resnet |
128,512. 128,512. 128,128. 128,1152.
single eye 训练思路
在每一个epoch里分别训练和测试,每完成一个epoch训练后,保存权重。
每一次训练,每一个batch(即每一个iteration)中,左右眼分别过Resnet34,得到长度为512输出,24维landmark过线性层得到长度为128的输出,之后这3个输出concatenate成1152的输出。再过fc(两次linear),输出。

问题
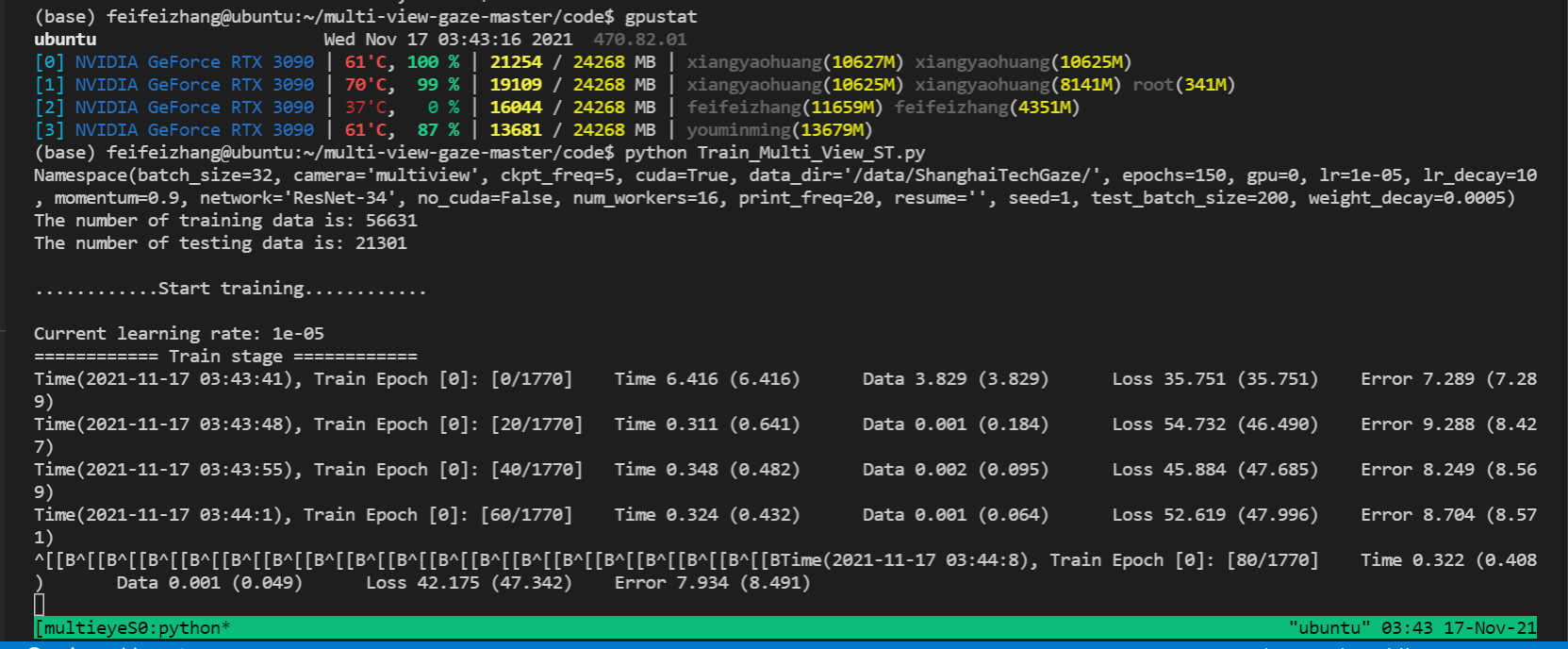
路径出错
结果
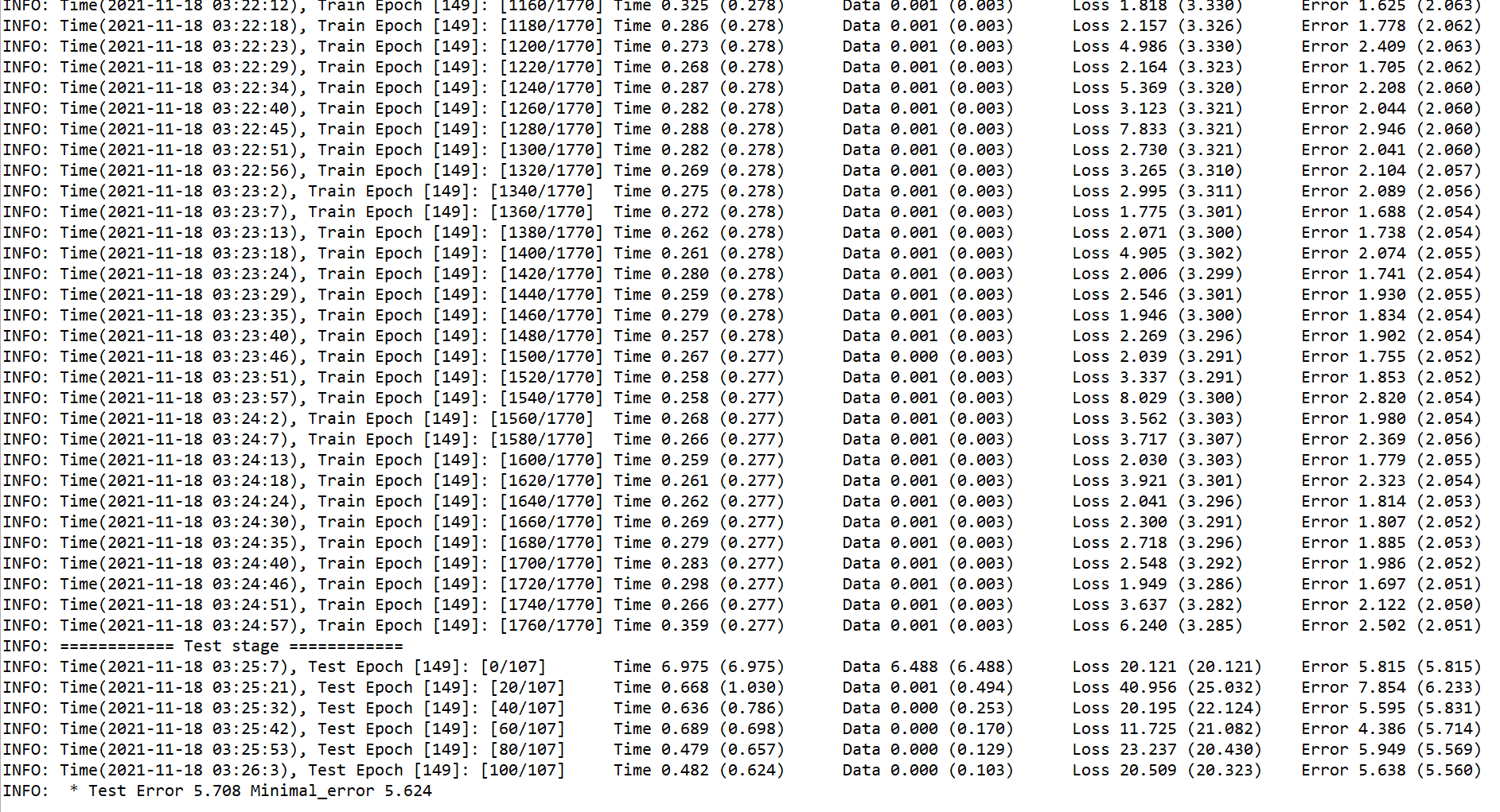
眼睛的位置是瞳仁的中心?还是眼周做平均
dongzelian/multi-view-gaze: Multi-view gaze estimation (github.com)
todo:多视角怎么bp