Funes Mora K A, Monay F, Odobez J M. Eyediap: A database for the development and evaluation of gaze estimation algorithms from rgb and rgb-d cameras[C]//Proceedings of the Symposium on Eye Tracking Research and Applications. 2014: 255-258.
评价:用于开发和评估来自RGB和RGB- d相机的注视估计算法的数据库
针对的问题:缺乏一个共同的基准来评估从RGB和RGB- d数据的凝视估计任务。
本文的目的:引入一个新的数据库和一个共同的框架来克服缺乏一个共同的benchmark这一局限性,用于注视估计方法的训练和评价。可以评估算法鲁棒性 。
i)头部姿势变化;
ii)人变化;
iii)环境和感知条件的变化和
iv)目标类型:屏幕或3D对象
数据集采集设置
Set-up
Kinect:这种消费设备提供标准(RGB)和VGA分辨率(640×480)和30fps的深度视频流。
高清摄像头:Kinect设计的视场更大,对用户移动性的限制更少,但30fps的深度视频流。这对于基于VGA分辨率的眼球追踪来说是个问题。因此,我们也使用了全高清相机(1920x1080), 25fps记录场景。
led:两个摄像头都可见的5个led用于同步RGB-D和HD流。
平面屏幕:使用一个24英寸的屏幕来显示一个可视目标。
小球:使用直径为4cm的小球作为视觉目标,有两个目的:在3D环境中作为视觉目标,在RGB和深度数据中都具有识别力,从而可以精确跟踪其3D位置(见第3节)。
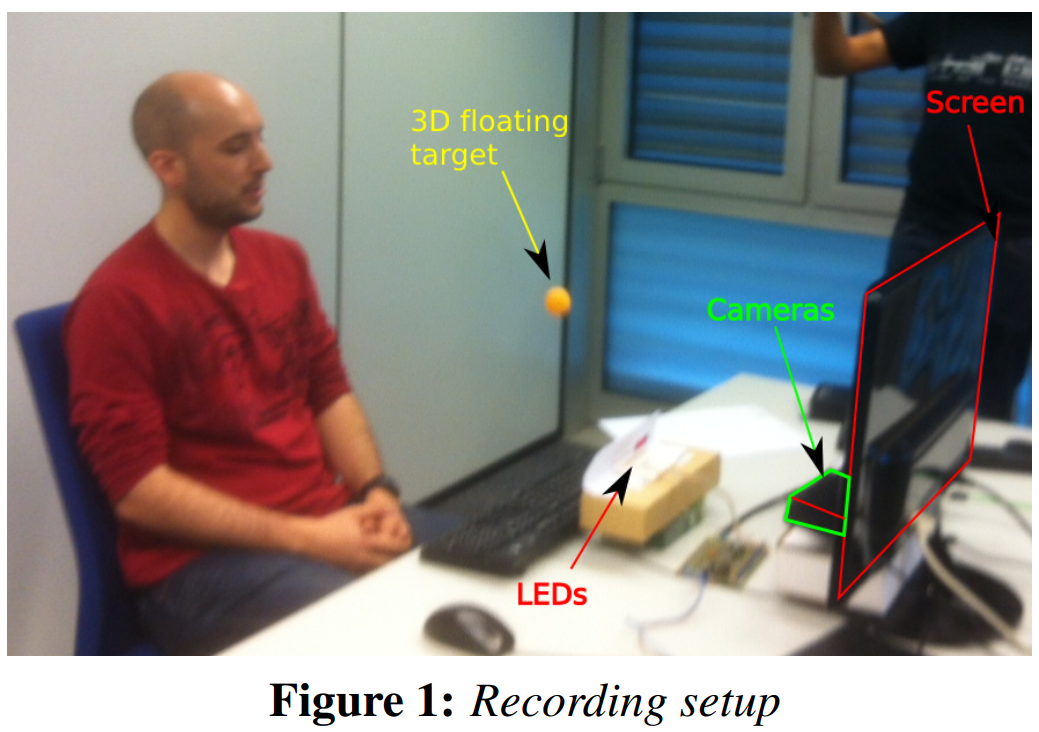
如图1所示,摄像头位于电脑屏幕正下方,这样可以从下方观察参与者的眼睛,尽量减少眼皮遮挡。参与者被要求在一定距离内坐在装置前面,这取决于视觉目标的类型(见下一段),并凝视指定的视觉目标。没有在说话活动、面部表情等方面给出指示。
Recording sessions
为了评估注视估计算法的不同方面,我们设计了一组记录会话,每个会话的特征是四个主要变量的组合,影响注视估计的准确性:视觉目标,头部姿势,参与者和记录条件。这些措施说明如下:
Discrete screen target
离散目标(DS)屏幕上,一个小圆匀画每1.1秒随机位置在计算机屏幕上,
Continuous screen target
屏幕连续目标(CS),圆圈沿着一个随机2 s轨道移动,以获得注视运动更平稳的例子。
3D floating target
3D浮动目标(FT):一个直径4厘米的球挂在一根细线上,这根细线附着在一根棍子上,在摄像机和参与者之间的3D区域内移动。与屏幕上的目标相比,参与者离相机的距离更大(1.2米而不是80-90厘米),以便有足够的空间让目标移动。
头部姿势。
为了评估方法对头部姿势的稳健性,要求参与者保持注视视觉目标,同时
(i)面对屏幕保持近似静止的头部姿势(静态情况,S);
(ii)进行头部运动(平移和旋转translation and rotation),以引入头部姿势变化(Mobile case, M)。
记录的条件
对于参与者12、13和14,在两种不同的条件下(记为A或B),一些进程被记录了两次:不同的日子、光照和与相机间的距离
总结。记录了94个2 - 3分钟的会话,总共获得了超过4小时的数据。每个会话由字符串“P-C-T-H”表示,它指的是参与者 participan id P=(1-16),记录条件conditions C=(A或B),使用的目标target T=(DS, CS或FT)和头部姿势 head pose H=(S或M)。录音示例如图2所示。

记录数据样本使用:a-c) RGB-D相机;d-e)高清相机,原始图像的640×480pixels patch显示用于与VGA分辨率数据进行比较。在这些例子中,参与者注视的是:a,d)头部保持静止的屏幕目标;b)静态头姿的浮动目标;c,e)移动头部时浮动目标。
Data processing
除了原始数据本身,还提供了额外的信息,这些信息对推导地面真相测量至关重要,或者只是对开发数据集和运行实验很有用。如何估计它们的更多细节可以在[Funes Mora et al. 2014]中找到。
RGB-D sensor calibration
RGB-D传感器校准。提供了RGB-D立体集成的校准参数,这些参数是使用开源校准工具箱获得的[Herrera C. et al. 2012]。这允许结合RGB-D数据到一个有纹理的3D表面。
RGB-D to screen calibration
RGB-D屏幕校准。提供摄像机坐标系统(3D)和2D屏幕坐标之间的校准。
RGB-D and HD camera synchrony and calibration
RGB-D和高清相机同步和校准。由于使用了5个led,高清数据与RGB-D视频流同步[Funes Mora等人,2014]。实现了两摄像机间的标准立体标定。
Head pose and eyes tracking.
对于每个参与者,我们使用[Funes Mora和Odobez 2012]中描述的方法,将一个3D Morphable Model [Paysan et al. 2009]与深度数据拟合,从而创建一个与他/她特定面部形状相对应的3D网格。此外,给定这个模板,我们使用迭代最近点(ICP)算法跟踪3D头部姿势,然后从该算法得到眼球在相机3D空间中的近似位置。
Floating target tracking
漂浮目标跟踪。对于使用一个球作为可视目标的记录会话,我们提供了球在每个时间步t的3D中心,使用彩色滤波和ICP拟合计算。
Manual annotations
手工注释。进一步的手工注释,当数据被认为是不可靠的注视估计(和评价)提供。这对应于眨眼的时刻,或者当这个人分心的时候(没有看目标)。手动注释是针对涉及屏幕目标的正面会话进行的。鉴于这些情况的发生率很低,我们目前没有在其他会话中对其进行标记(它将被视为噪音)。不过,如果需要,还可以做进一步的注释。
Considered tasks
文章描述了用于评估注视估计算法的准确性及其对不同变量(如头姿、光照条件等)的鲁棒性的不同评估基准。首先总结评估协议框架的主要元素,包括性能度量,然后列出一组基准。
Evaluation protocol and measures
本节介绍实验描述中涉及的概念:什么被理解为注视估计算法;训练、测试和评估集的定义 train, test and evaluation sets;性能测量。
Gaze estimation algorithm注释估计算法
注视估计的输出取决于应用程序。这里考虑两个非常常见的情况:一个3D gaze ray单位向量;或屏幕坐标系Screen coordinates上的二维像素,这通常用于基于屏幕的HCI应用程序。提供额外信息(摄像机-屏幕校准),可以从3D凝视射线推断屏幕坐标[Funes Mora等人,2014]。
训练数据集的真值包含3d视线估计p和2d视线估计s,给出一定的参数,p可以从s中计算处理。考虑不同的方法来收集这些训练样本:时间,即数据对应于一个较大的视频的部分;或结构化:训练数据以结构化的方式收集,以满足注视估计算法的特定要求(例如,获取最接近屏幕上预定义数量的特定真值的样本)。
测试集假设它是帧索引范围内较大视频的时间序列。
验证集将用于计算算法性能。这是测试数据的一个子集,通过移除数据或地面真相被破坏的样本,由于眨眼和分心,极端的头部姿势,影响眼睛的可见性(例如,鼻子遮挡)。
Predefined experimental protocols
为了在不同的实验条件下比较算法和它们的优点,定义了一组协议,它们的区别主要在于用于训练和测试算法的数据库。注意,该数据集有两种主要类型的视觉目标:3D浮动目标(FT)和屏幕目标(CS或DS)。因此,定义的评价方案可以根据首选的视觉目标而变化。总结如下。更多细节见[Funes Mora et al. 2014]。
Protocol 1:注视估计的准确性。在本方案中,我们评估了一个算法$H$的准确性,在所有参数的最小变化下,更准确地说,对于一个session s,其中唯一的变化是注视本身,我们将训练集定义为s的前半部分。测试集定义为s的后半部分。这种实验的结果是平均角误差$\epsilon$◦。可以根据视觉目标的类型导出相关会话。
Protocol 2:头姿变化的鲁棒性。这里的目的是测量由于头部姿势的变化,凝视的准确性下降了多少。首先进行静态头姿(S)实验,然后进行头姿变化(M)实验,然后报告两种情况下的平均误差以及算法对头姿变化的敏感性。
Protocol 3:个人依赖。目的是评估一种方法推广到不可见用户的效果。这可以通过 leave-one-person-out留一法实验装置来实现。
Protocol 4:环境变化。最后,本案例的目标是研究一种方法在不同条件下的泛化特性。为此,可以对参与者12、13和14进行实验,在不同的设置和光照条件下记录会话。
Evaluation protocol example
为了说明数据集的用法,这里我们详细描述了与其中一个基准相关的数据:3D浮动目标的注视估计精度协议(Protocol 1),并使用RGBD流作为注视估计算法的输入数据。注意,这种配置是数据集中最具挑战性的情况之一,对于这种情况,典型的眼睛图像大小为≈14×10pixels。
头部姿势和3D目标跟踪
在表1中,我们显示了每个会话对应的帧总数,以及我们能够成功估计头部姿势或视觉目标位置的帧数。注意,头部姿势的召回率很高(99.9%),因为在本方案中,涉及近额 near frontal和静态头部姿势的人。由于目标在相机的视野之外,或者太靠近传感器导致缺失深度数据,可视目标位置的召回率较低(69%)。尽管如此,这些数字表明有大量的凝视标记数据可供实验使用(每次记录大约100秒)。
此处的召回率指的应该是拍到所有数据后,可以使用的数据。可以看到表格1中,第三行Training和第四行Testing加起来的和大约等于第三行Ball Target的数目。
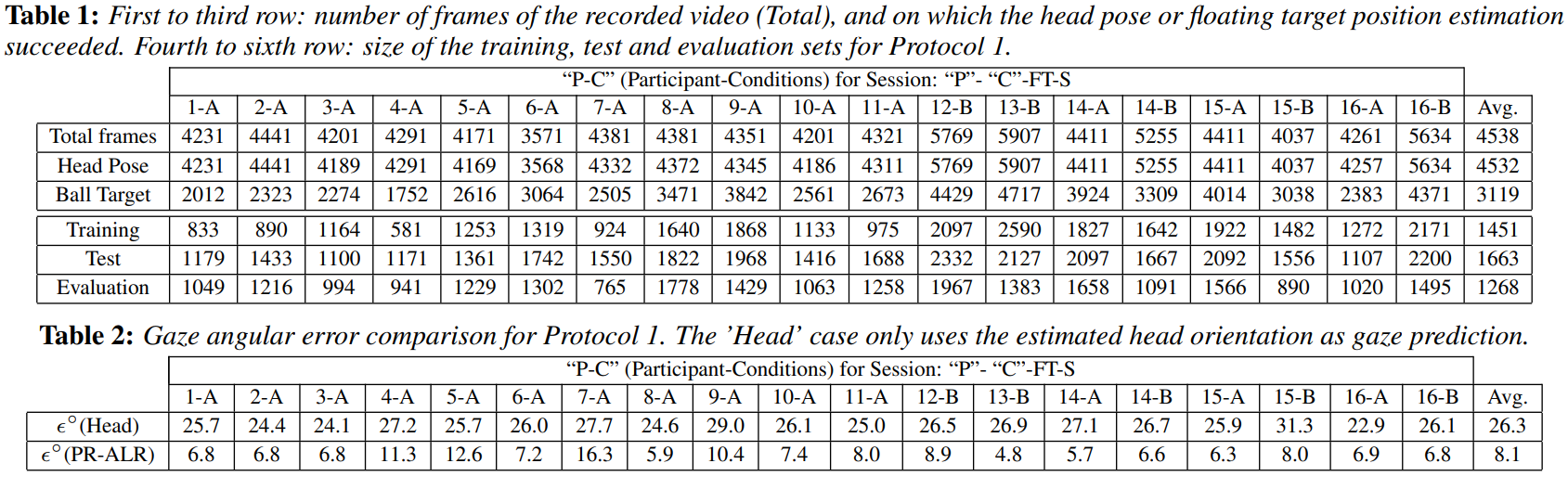
表1:第1 - 3行:记录的视频帧数(Total),头部姿态或浮动目标位置估计成功(可用数据?)。第四到第六行:Protocol 1的训练、测试和评估集的大小。
表2:协议1的注视角度误差比较。“头”的情况下,只使用估计的头部方向作为凝视预测。
Protocol sets每个会话被平均分为两个时间区域:前半部分是训练集,后半部分是测试集。测试集test set被筛选以定义评估集evaluation set(下一节将描述标准)。表1显示了每组样本的数量(仅考虑已知头姿和目标位置的样本)
目光估计方法。我们实现了一种基于RGB-D的方法[Funes Mora和Odobez 2012],该方法依靠RGB-D数据将眼睛图像的视点矫正为典型的头部姿势。我们将这种方法称为位校正自适应线性回归pose-rectified adaptive linear regression(PRALR)。对每个参与者,从训练集中提取42个样本的注视外观模型。这些样本有规律地分布在注视偏航值之间的±40◦和注视仰角值之间的±30◦。由于PR-ALR是一种基于插值的方法,我们只考虑凝视外观模型中使用的数据的凸壳内的测试样本,即评价集evaluation set仅由地面真值测量遵循相同的偏航和仰角凝视标准的测试样本组成。
估计精度。为了证明数据的可变性,我们计算了在假设参与者注视前方时获得的注视角度误差,即假设注视方向是由头部姿势方向给出的。实验结果如表2所示。注意,这两种方法都输出3D凝视光线,我们使用相同的评估集,因此这些结果可以直接进行比较。“头部”案例显示的角度误差提供了数据中凝视的大变化性的证据。采用PR-ALR注视估计算法后,注视估计的精度得到了显著提高。
Head可能是使用头部的方向代替视线的方向?
然而,与文献报道的结果相比,误差仍然很高,这主要是由于低分辨率(~ 14×10每只眼睛像素)和低对比度(例如参与者7-A是黑色皮肤)。此外,异常值(眨眼、分心等)还没有从评估集3中剔除。注意,这是我们的数据中最具挑战性的场景之一,这个实验足以演示如何使用数据、定义的协议以及如何描述一个实验。
Conclusion
我们描述了一个新的数据集,用于开发和评估来自RGB或RGB- d数据的注视估计算法,解决了社区对标准化基准的需求。
数据库丰富多样,因为它代表了这项任务的主要挑战。大多数变量(头部姿势,人,条件和目标类型)已经被系统地隔离,目标是恰当地描述注视估计在准确性和稳健性方面的不利条件。
描述了记录方法和所记录数据的摘要。我们还列出了提供给用户的额外信息,如设置校准,目标位置,头部和眼睛跟踪信息。我们更详细地描述了一个作为使用实例的实验。我们相信该数据库对研究人员具有很高的价值,因为它将有助于促进注视估计技术在较少约束条件下的发展。
数据集组织结构
Data
Data下文件夹命名格式为“P-C-T-H”,指的是参与者 participan id P=(1-16),记录条件conditions C=(A或B),使用的目标target T=(DS, CS或FT)和头部姿势 head pose H=(S或M)。
每个文件夹下包含三个视频,3个视频采集设备的参数文件。
利用相机内外参数先把depth和rgb对齐。
1 | rgb_vga_calibration.txt |
1 | depth_calibration.txt |
1 | rgb_hd_calibration.txt |
1 | screen_coordinates.txt |
Is there something wrong with the 3D coordinates given in the screen_coordinates.txt file?
The 2D coordinates are perfectly fine. However, the given screen 3D coordinates are actually referred to the RGB camera coordinate system. To refer them to the World Coordinate System (WCS), you’d have to apply the transformation described in Equation 1 from this document.
当目标是屏幕上的小圆圈的时候,是怎么获得3D坐标的呀?
对于悬浮目标,坐标储存在ball_tracking.txt
1 | ball_tracking.txt |
1 | head_pose.txt |
1 | eye_tracking.txt |
todo
1.depth数据的处理,depth相机参数的使用。
2.depth相机参数中的k_coefficients、alpha、beta是啥?
数据预处理程序坐标转化部分
99行起
1 | head_rot = head[1:10] |
具体坐标系转换和遇到的问题分析
head_rot = np.dot(cam_rot, head_rot)
在世界坐标系中头部的旋转=相机外参X相机坐标系中头部旋转。
head_trans = np.dot(cam_rot, head_trans)
head_trans = head_trans + cam_trans
在世界坐标系中头部的平移 = 相机外参X相机坐标系中头部的平移 + 相机平移。
其实主要是感觉targe的坐标不知道是用什么拍到的,没有做任何的坐标变换,那就说明是使用世界坐标系中的相机拍到的,第三者视角的相机,可是这个相机怎么拍到带有深度的三维空间坐标信息呢?
解决方法:
1.查看14年官方给的demo中如何完成坐标转换。
2.相信代码作者,如法炮制depth。
20220205自己看代码的回答:screen_coordinate.txt中的label应该是在WCS中的,因此把左右眼的位置都进行了转化CCS->WCS。
HeadTo2d(head) 中要调试的时候看一下M以及vec = M[:, 2]的维度。
1 | def HeadTo2d(head):#shape(3,) |


???旋转矩阵的最后一列计算pitch、yaw???感觉奇怪???
若直接对head_pose用HeadTo2d(head)函数
[[ 0.99968746 0.02361175 -0.00821368]
[-0.0230888 0.99800243 0.05880524]
[ 0.00958576 -0.05859722 0.99823568]][-0.00822801 0.05883919]
代码中有一小段冗余,cam_rot*head_pose结果是
[[ 0.99968746 0.02361175 -0.00821368]
[ 0.0230888 -0.99800243 -0.05880524]
[-0.00958576 0.05859722 -0.99823568]][-3.13336465 -0.05883919]
20220211:😫w(゚Д゚)w就看不懂那个坐标转换,透视变换。其实不用看他的,对于FT目标,在相机坐标系中计算。看一下其他程序的处理方法吧!不要闭门造车,可以发邮件询问。
程序逻辑
每15帧取一帧
相机内外参数
一文带你搞懂相机内参外参(Intrinsics & Extrinsics) - TheLastRefugee的文章 - 知乎 https://zhuanlan.zhihu.com/p/389653208
多视图几何基础——深入理解相机内外参数 - 可乐加枸杞的文章 - 知乎 https://zhuanlan.zhihu.com/p/54139614
旋转向量
(21条消息) 罗德里格斯(Rodrigues)旋转向量与矩阵的变换_凌辰两点的博客-CSDN博客_rodrigues变换
旋转矩阵还可以理解为原向量围绕空间中某一个向量,直接一次逆时针旋转某一个角度得到。
(21条消息) 旋转矩阵、欧拉角之间转换_小磊在路上的博客-CSDN博客_旋转矩阵转欧拉角
欧拉角和旋转矩阵之间的转换 - 知乎 (zhihu.com)