本文主要介绍人脸关键点检测中使用的heatmap。并且会介绍Adaptive Wing Loss这篇文章中针对于heatmap损失函数的设计,以及它的实验结果。
heatmap介绍
参考了[2016CVPRW]Deep Alignment Network: A convolutional neural network for robust face alignment 3.3. Landmark heatmap
landmark heatmap 是landmark位置的强度最高,强度随着距离最近的地标的距离增大而减小的图像。
$H$是热图,$s_i$是第i个landmark,为了提高性能,可以只在每个地标周围以16为半径的圆圈内计算热图值。
上面的公式中使用了范数,也可在的每个关键点处绘制一个高斯分布来生成的热图。
[2019ICCV]Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
Xinyao Wang1,2Liefeng Bo2Li Fuxin1
1Oregon State University 2JD Digits
{wangxiny, lif}@oregonstate.edu,{xinyao.wang3, liefeng.bo}@jd.com
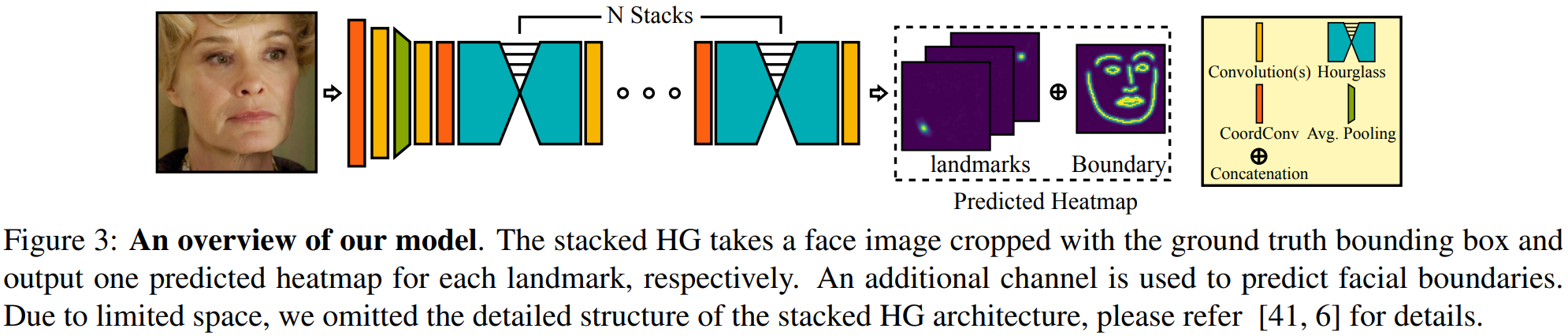
评价:提出了一种新的loss函数,称为Adaptive Wing loss,它具有适应性,这种适应性对前景像素损失的惩罚更大,而对背景像素损失惩罚较小。提出了加权损失图(Weighted Loss Map),为前景像素和“困难的背景像素”分配较高的权重,以帮助训练过程更多地关注对地标定位至关重要的像素。为了进一步提高面对齐精度,引入了边界预测和基于边界坐标的CoordConv。
针对问题:基于深度网络的热图回归已成为人脸关键点定位的主流方法之一。然而,对于热图回归中损失函数的研究却很少。
本文的目的:分析了人脸关键点检测问题热图回归的理想损失函数性质,并根据此设计了Adaptive Wing loss。该模型在像素级对真值热图进行更加准确的回归,然后利用预测的热图来推断关键点的位置。
热图分析:
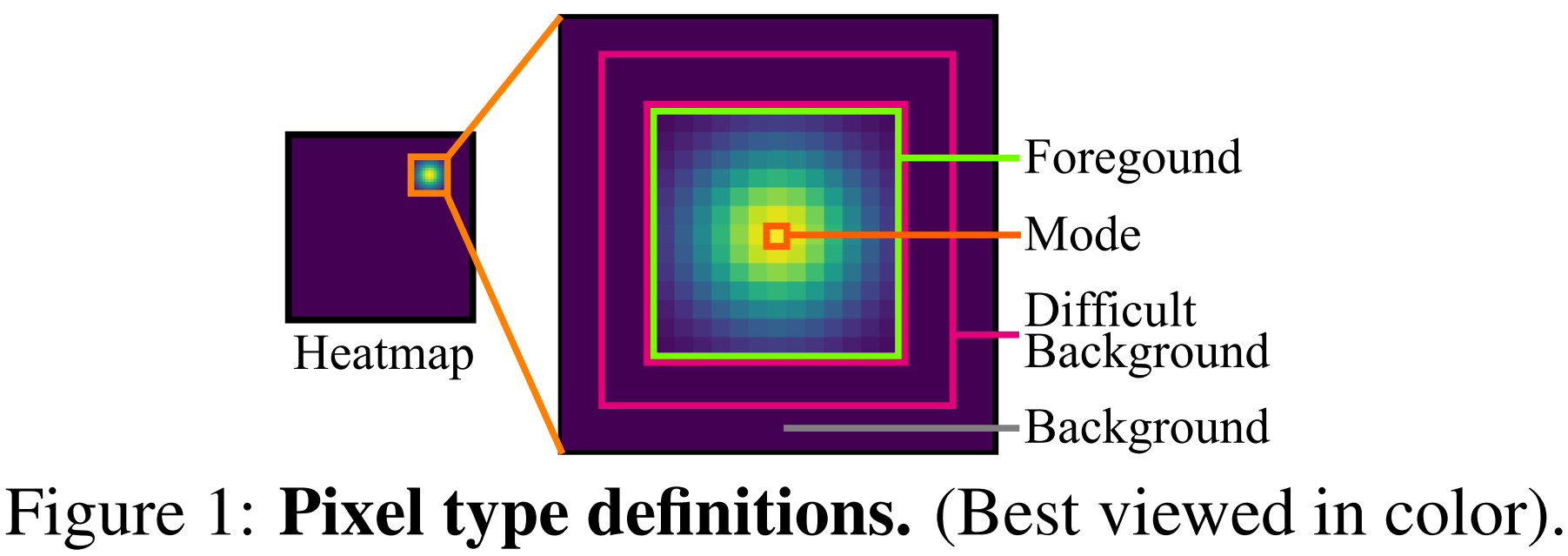
在热图中前景像素(具有正值的像素),特别是每一个高斯分附近的像素,对于准确定位关键点至关重要。这些像素上即使很小的预测误差也会导致预测偏离正确的模式。这些像素的预测误差即使很小,也会导致预测偏离正确的模式。
相反,准确预测背景像素(零值像素)的值就不那么重要了,因为这些像素上的小误差在大多数情况下不会影响地标的预测。
然而,困难背景像素(图1背景像素接近前景像素区域的像素)的预测精度也很重要,因为它们经常被错误地回归为前景像素,可能导致预测不准确。
heatmap regression中的常用的MSE loss
a. 均方误差对小误差不敏感,影响了对高斯分布模式的正确定位。
b. 在训练过程中,MSE loss对于所有的所有的像素都具有相同的损失函数和相等的权值,但是在热图上,背景像素多于前景像素。
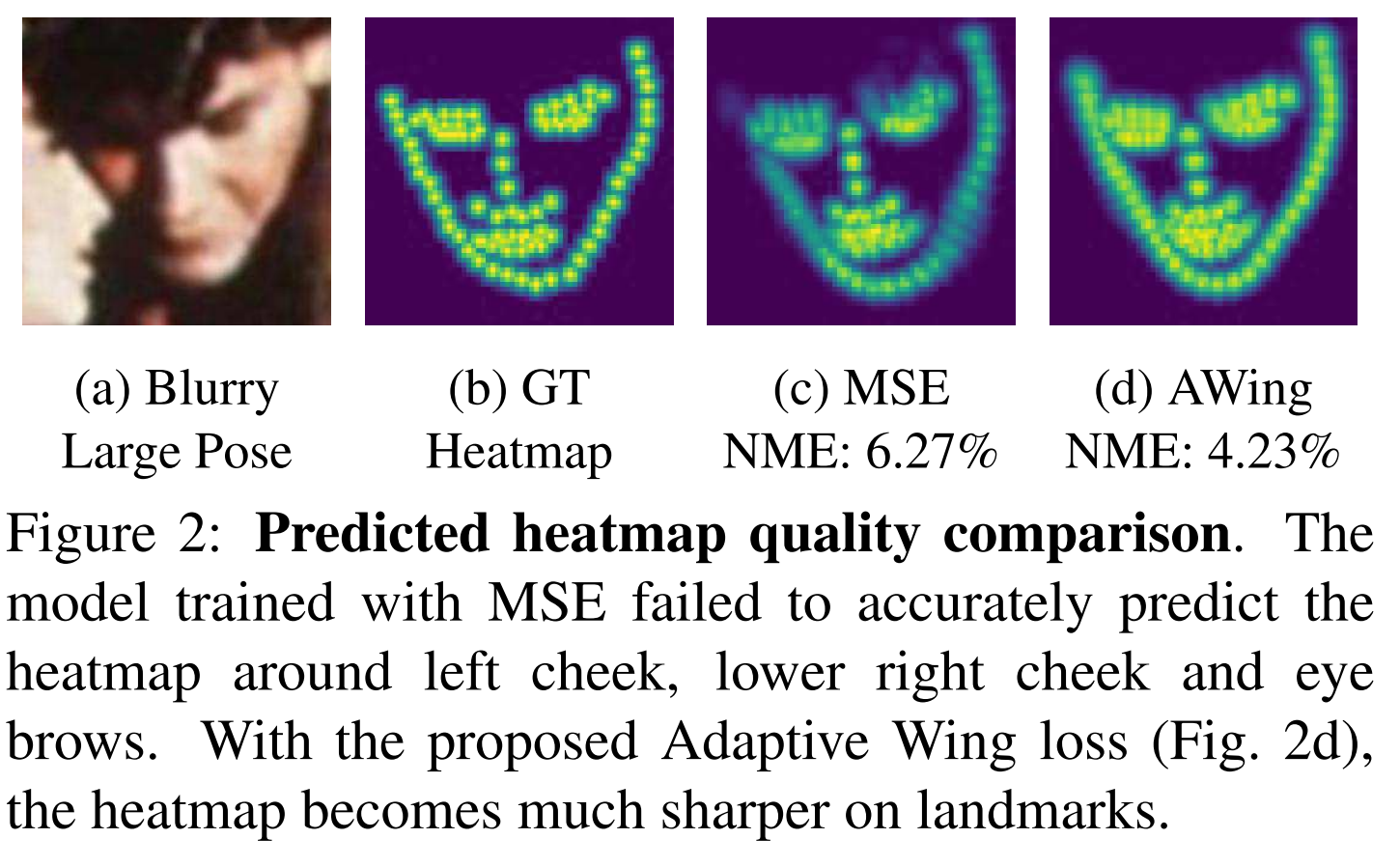
由于a)和b),使用MSE损失训练的模型所得的结果与ground truth热图相比,前景像素强度会被降低,会获得一张模糊和膨胀的热图。这种低质量的热图可能会导致对面部关键点的错误估计。
网络结构
损失函数的基本原理

•其中,N是训练样本的总数,H、W和C分别是热图的高度、宽度和通道。
•从稳健统计中引入一个概念。影响力是一个启发式工具,在稳健统计中用来研究估计量的性质。
•在收敛时,在收敛时,所有误差的影响必须相互平衡。因此,具有较大梯度幅值的像素的正误差(影响较大)需要用影响较小的许多像素上的负误差来平衡。与梯度较小的错误相比,梯度较大的错误也会在训练中更被关注。如何对小误差有一个相对较高的关注是设计的出发点之一。
不同loss对于大梯度和小梯度误差影响力分析以及连续性分析

a. 常用于热图回归的均方误差损失函数。均方误差损失的梯度是线性的,因此误差小的像素影响小。该属性可能导致训练收敛,而许多像素仍有小误差。因此,用均方误差损失训练的模型倾向于预测模糊和扩大的热图。
b. L1loss具有恒定的梯度,因此误差小的像素与误差大的像素具有相同的影响。然而,L1损失的梯度在零点不是连续的,具有正误差的像素的数量必须恰好等于具有负误差的像素的数量。
c.当误差较大时具有恒定梯度,当误差较小时具有大梯度的wing损失。因此,误差小的像素将被放大。
仍然不能克服其梯度在零点时的不连续性。不适用于热图回归。
因为在所有背景像素上计算wing损失,背景像素上的小误差具有不成比例的影响。训练一个在这些像素上输出零或小梯度的神经网络是非常困难的。
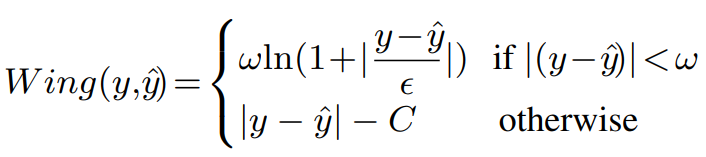
理想的loss设计
•误差较大
•loss函数具有恒定的影响,这样它将对不准确的注释和遮挡具有鲁棒性。
•误差小
•对于前景像素,影响应该开始增加,以便训练能够集中于减少这些误差。当误差非常接近零时,这种影响应该会迅速减小,这样这些“足够好”的像素将不再被关注。减少正确估计的影响有助于网络保持收敛,而不是像L1和wing loss那样振荡。
•对于背景像素,梯度应该表现得更类似于均方误差损失,即随着训练误差的减小,梯度将逐渐减小到零,因此当误差较小时,影响将相对较小。该属性减少了背景像素上的训练的关注,稳定了训练过程。
- Adaptive Wing loss设计
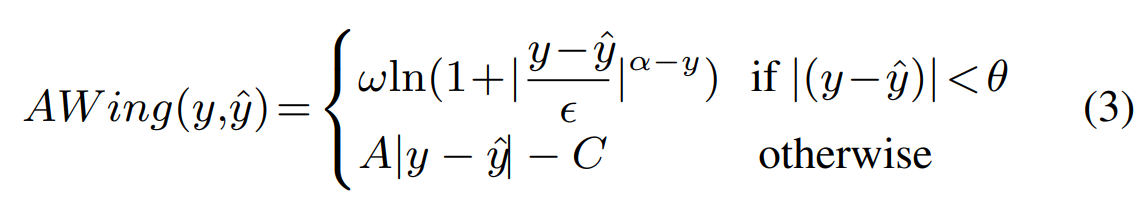

损失函数在零点平滑。
区分前后景像素
在具有64 × 64热图和7×7高斯大小的面部标志定位的典型设置中,前景像素仅构成所有像素的1.2%。为这种不平衡的数据分配相同的权重可能会使训练过程收敛缓慢,从而导致较差的性能。为了进一步建立网络聚焦前景像素和困难背景像素(接近前景像素的背景像素)的能力,引入加权损失图来平衡不同类型像素的损失。前景像素和困难背景像素1,其他像素0。

网络直接回归出热图,从热图中得出关键点。
使用热图的好处:
1.相比于fc回归出位置,cnn输出heatmap,cnn由于参数共享的性质,相比于fc有更好的泛化性能。
2.heatmap同样捕捉了前景(关节点)与背景的对比关系,同样可以用来指导网络进行学习。
3.很多任务中,目标点其实很难准确的被某一个像素位置定义的,也就很难被准确的标注。目标点附近的点其实也很像目标点,我们直接将其标为负样本,可能给网络的训练带来干扰,将其用高斯函数做一个“软标注”,网络也就更好收敛。
- 加上高斯图,也能够给网络的训练增加一个方向性的引导,距离目标点越近,激活值越大,这样网络能有方向的去快速到达目标点。
在低分辨率的图片中此方法相比于与其他方法,使用热图可以跟好的捕捉前景和后景的关系,类似于更加关注图片中锐化的信息,可能是比较明显的角点信息。
adapt_wing_loss论文测试效果
此论文只给了测试代码以及预训练好的模型
真值绿色,红色为预测值。
下图为nme > 0.1的失败案例。失败的原因是图片本身有遮挡,或者图片清晰度不高,或者是人脸为大角度姿势。
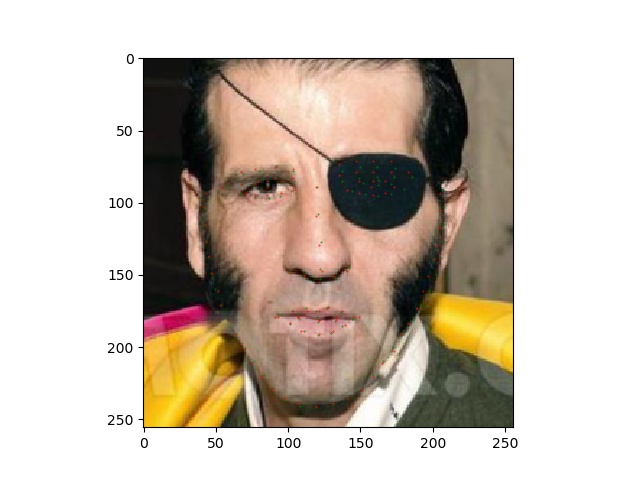
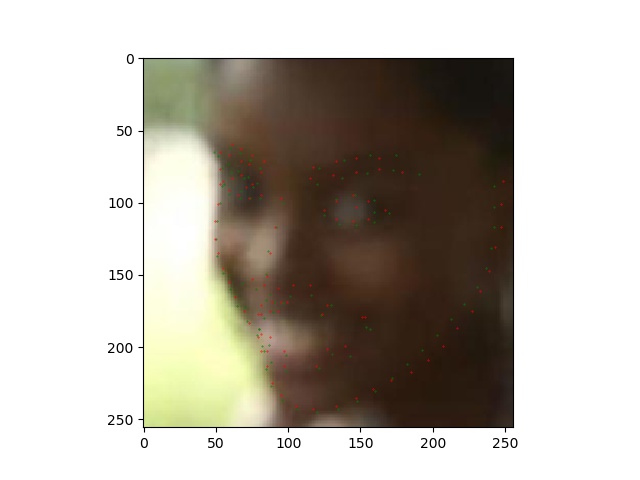



1 | 原图 |
数据集与处理方式
300w的数据集除了private外,没有官方边界。
WFLW提供的边界框不是很准确。
因此在两个维度上都将边界框放大了10%,300W直接裁剪人脸。
数据集WFLW#7500训练 2500测试。
人脸多种属性、关键点标注数据集,包含了10000张脸,其中7500用于训练,2500张用于测试,共98个关键点。除了关键点之外,还有姿态,表情,光照,妆容,遮挡,模糊。
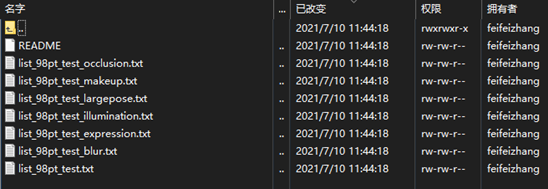
list_98pt_rect_attr_train_test.txt是98X2关键点+4左上右下+6属性+图片名称 = 196 +4+6+1 = 207 list_98pt_test.txt196 + 名字 =197。