本篇文章文章主要介绍PFLD: A Practical Facial Landmark Detector这篇文章。
[2019CVPR]PFLD: A Practical Facial Landmark Detector
2019CVPR Xiaojie Guo1, Siyuan Li1, Jinke Y u1, Jiawan Zhang1, Jiayi Ma2, Lin Ma3, Wei Liu3, and Haibin Ling4
1Tianjin University2Wuhan University3Tencent AI Lab4Temple University
关键点检测四大挑战
•挑战1 ——局部变化。 表情、局部极端光照(如高光和阴影)和遮挡会给人脸图像带来部分变化和干扰。一些区域的关键点可能会偏离它们的正常位置,甚至消失。
•挑战2——全局变化。 姿态和成像质量是全局影响图像中人脸外观的两个主要因素,当人脸的全局结构被错误估计时,会导致很大一部分关键点定位出现偏差。
•挑战3 —— 数据不平衡。在浅层学习和深层学习中,一个可用的数据集在其类/属性之间呈现不平衡的分布是很常见的。这种不平衡很可能使算法/模型不能正确地表示数据的特征,从而在不同的属性上提供不令人满意的精度。
原因:在现实生活中,获得完美的脸几乎不可能。换句话说,人脸经常暴露在不受控制甚至不受约束的环境中。在不同的光照条件下,外观有很大的姿态、表情和形状变化,有时伴有部分遮挡。

上图提供了几个这样的示例。此外,为数据驱动方法提供足够的训练数据也是模型性能的关键。假设出于数据平衡的考虑,在不同的条件下捕捉几个人的面孔可能是可行的,但这种收集方式不现实。
上述挑战大大增加了精确检测的难度,要求检测器具有鲁棒性。
•挑战4 ——模型效率。模型大小和计算要求。机器人、AR和视频聊天等任务需要在配备有限计算和内存资源的平台(如智能手机或嵌入式产品)上实时执行。这一点特别要求关键点检测器具有小的模型尺寸和快速的处理速度。
方法简介
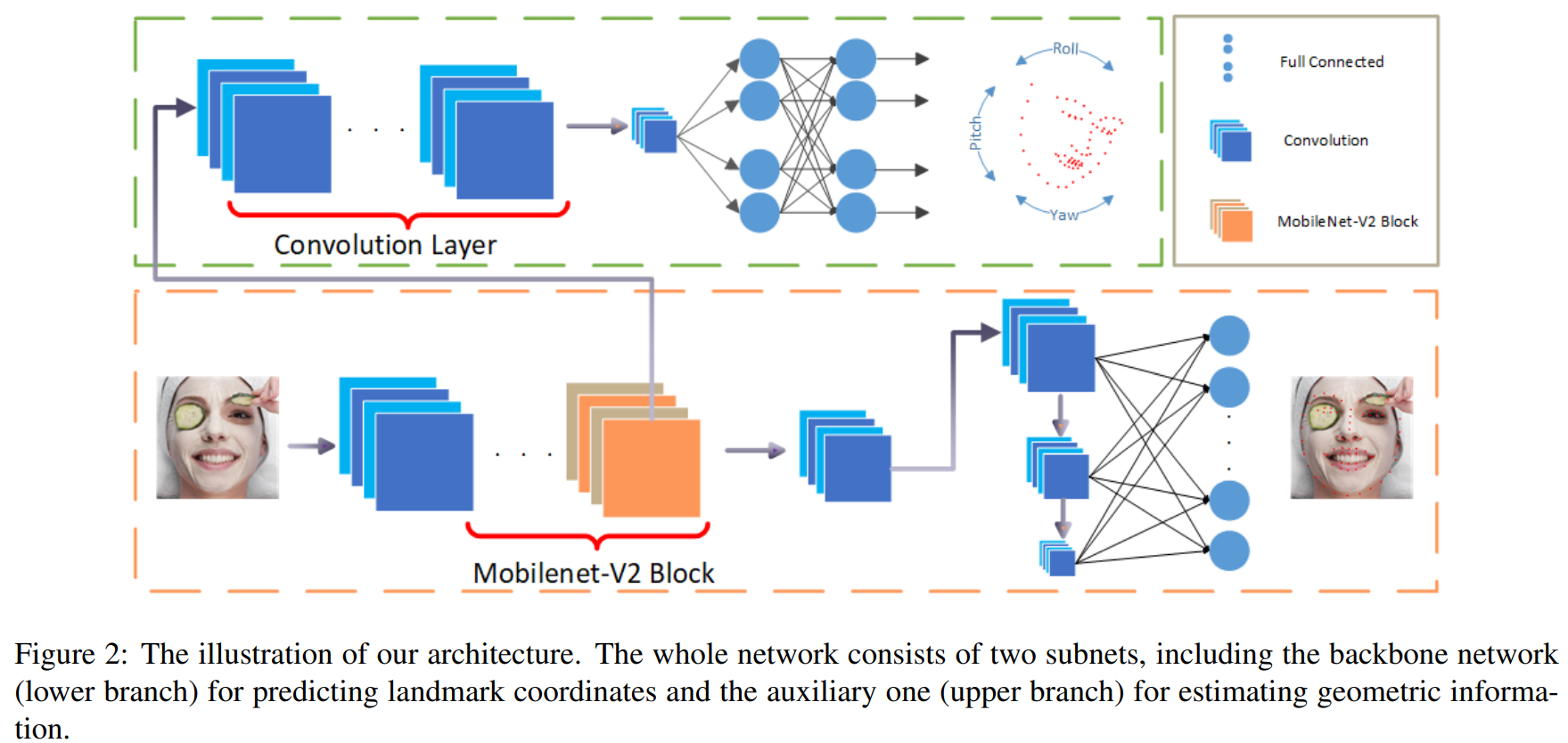
•与局部变化相比,全局变化极大地影响整个地标集。为了增强鲁棒性,使用网络上分支来估计每个人脸样本的几何信息,并随后正则化地标定位。辅助网络(上分支)可以输出目标角度,估计三维旋转信息,包括偏航yaw、俯仰pitch和滚转角roll。有了这三个欧拉角,就可以确定头部的姿态。
•预测地关键点的骨干网(下分支)中使用了MobileNet代替了传统卷积,骨干网的负荷大大减少,从而加快了速度。此外,网络可以通过根据用户的需求调整mobilenet的宽度参数来压缩,使模型更小、更快。
上下分支网络设计有效的应对了挑战2和挑战4。
扩大感受野,更好地捕捉人脸的全局结构,增加了一个多尺度全连通层,用于精确定位图像中的关键点。
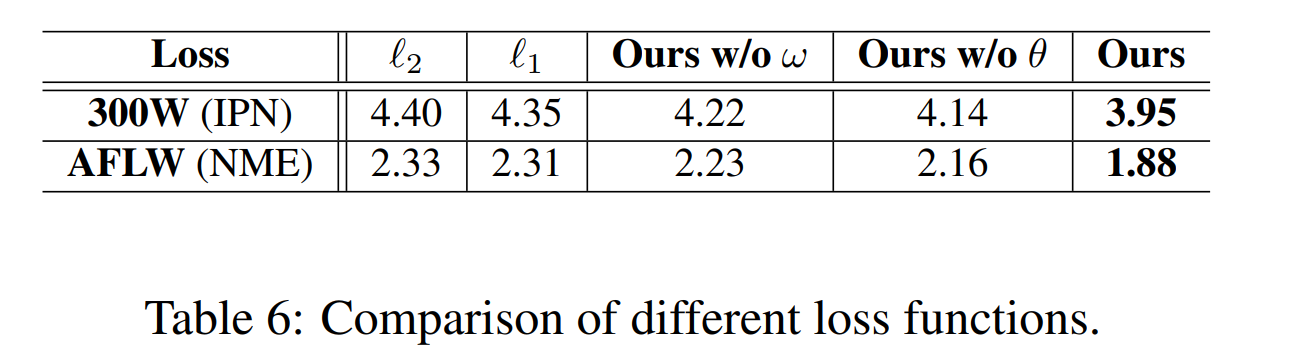
针对于几何变化和数据不平衡问题设计的loss函数
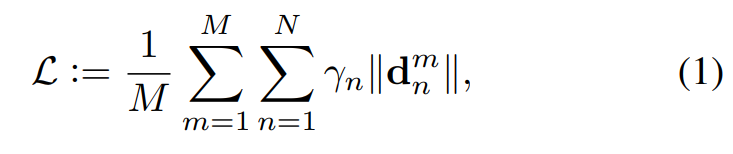
第m个输入的第n个地标,N是每个检测人脸预定义的标定点数量,M表示每个过程中训练图片的个数。$d$代表估计值与真值之间的偏差。
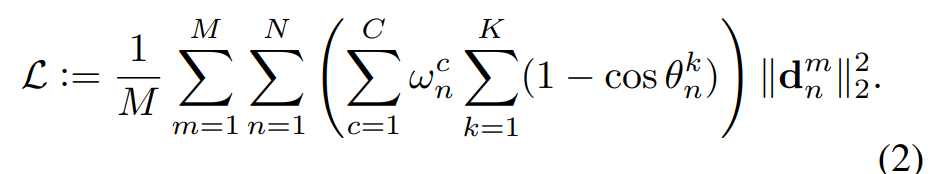
公式(2)表示地面实况和估计的偏航、俯仰和滚转角之间的偏离角。显然,随着偏离角度的增加,惩罚力度会增加。此外,将样本分为一个或多个属性类,包括侧面、正面、抬头、低头、表情和遮挡。C表示类。
加权参数$ω_c^n$根据属于c类的样本的分数进行调整(论文中采用倒数)。这样设计loss,对于数量少的样本惩罚系数会增大,对于数量多的样本惩罚系数会减小。
很容易得到式(2)中的$\sum_{c=1}^C \sum_{k=1}^K(1−cosθ^k_n)$作为式(1)中的$\gamma_n$。式中$θ^1、θ^2、θ^3$(K=3)表示地真值与估计的偏航角、俯仰角、滚转角的偏差角,当误差大时惩罚系数大,当误差小时惩罚系数小。
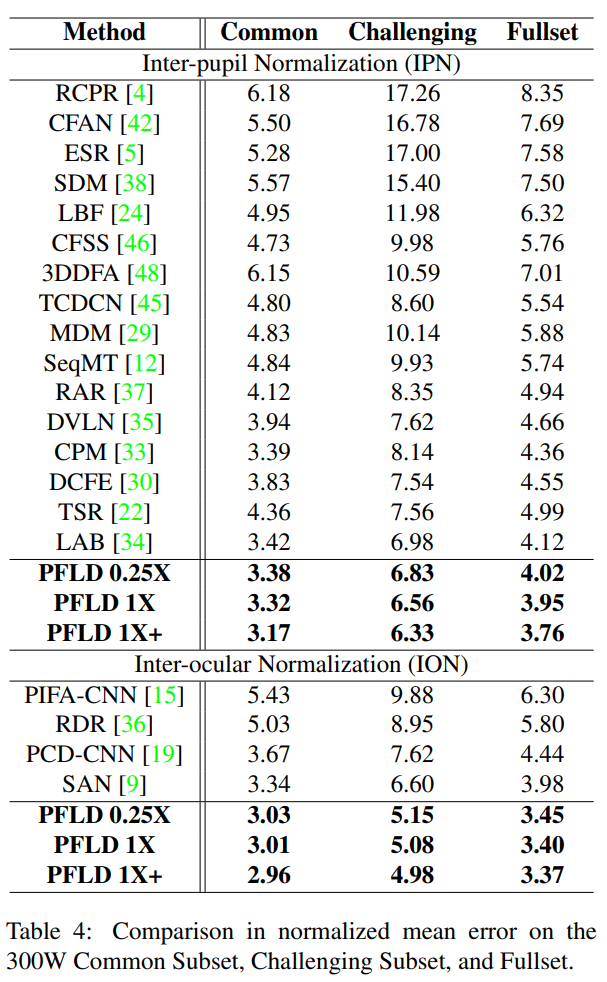
实验结果