GAN
分辨模型,分到属于哪一个类别。生成模型生成数据本身。
主要思路:
生成模型G,生成数据本身的分布。辨别模型D,估计数据是从真正的训练数据分布当中得来的还是从G生成得来的。
生成模型G是尽量让判别模型D犯错。
深度学习不仅仅是深度网络,而且也是学习整个深度数据分布的一个特征表示。深度学习对于辨别模型有比较好的效果,但对于生成模型的研究比较少,要去近似那个分布计算似然函数。
G:造假者。提高造假币的能力。
D:警察。提高判断假币的能力。
希望最后造假者的能力很强,而警察分不清真币还是假币。这样就能生成跟真实一样的数据了。
生成模型G的框架是MLP,它的输入是随机的噪声,MLP可以把噪声拟合到任意的分布。判别模型也是MLP,两个网络都可以反向传播学习参数。
不是计算出一个模型的参数,而是学一个模型近似结果即可。坏处是不知道真正的分布长啥样,好处是计算简单。
adversarial example生成一些假的样本。能够互动到分类器,从而测试整个算法的稳定性。\
对抗网络模型
生成器生成对于数据$x$上的分布$p_g$,一开始 初始化模型为$p_z(z)$,生成模型$G(z,θ_g)$把$z$映射成$x$,判别器$D(x,θ_d)$输出一个标量,用于判别是生成的数据还是真实数据。
对抗损失
假如$D$是完美的,对于一张真图片$x$,$D(x)=1$。
$G(z)$是生成的,假如$D$是完美的,$D(G(z))=0$。
在这种情况下,两项都为0。
$D$尽量使数据分开,$G$使得生成的数据使得$D$分不开。第一项使得$D$尽可能正确,第二项使$D$犯错。
希望最后生成数据和真实数据在分布上一样,判别器无能为力,对于生成数据和真实数据都输出0.5。
每次迭代先更新判别器,再更新生成器,糊弄判别器。$D$每次不能更新的太小,也不能更新的太完美。
GAN网络不容易收敛。
GAN是无监督学习,没有用到label。GAN使用有监督学习的损失来做无监督学习,label来自于数据,数据是采样的还是生成的。
最大似然估计的原理
存在即合理。
抽出一组样本的概率会随着概率模型参数变化而变化的。
一个小概率事件可以认为他不发生,但是现在发生了,这种概率达到了最大,就认为它是最大的。认为抽样样本出现时候的概率达到最大值时的模型参数就是分布的参数。于是就变成了求函数最大值。
求导数,求导数值为0的参数值。
KL散度
在知道p的情况下至少需要多少个比特把q给描述出来。
cycle gan
图像到图像的翻译 (Image-to-Image translation) 是一种视觉上和图像上的问题,它的目标是使用成对的图像作为训练集,(让机器)学习从输入图像到输出图像的映射。然而,在很多任务中,成对的训练数据无法得到。
我们提出一种在缺少成对数据的情况下,(让机器)学习从源数据域X到目标数据域Y 的方法。我们的目标是使用一个对抗损失函数,学习映射G:X → Y ,使得判别器难以区分图片 G(X) 与 图片Y。因为这样子的映射受到巨大的限制,所以我们为映射G 添加了一个相反的映射F:Y → X,使他们成对,同时加入一个循环一致性损失函数 (cycle consistency loss),以确保 F(G(X)) ≈ X(反之亦然)。
在缺少成对训练数据的情况下,我们比较了风格迁移、物体变形、季节转换、照片增强等任务下的定性结果。经过定性比较,我们的方法表现得比先前的方法更好。
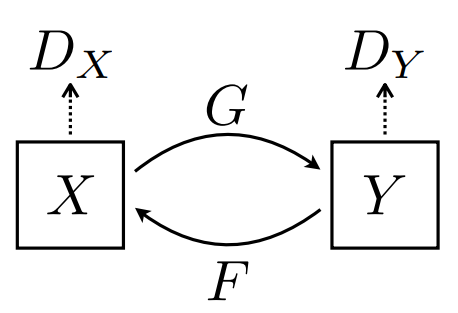
我们的目标是学习两个数据域 X 与 Y 之间的映射函数,定义数据集合与数据分布,与模型的两个映射,其中:
另外,我们引入了两个判别函数:
- 用于区分{x} 与 {F(y)} 的
- 用于区分{y} 与 {G(x)} 的
。
我们的构建的模型包含两类组件(Our objective contains two types of terms):
- 对抗损失(adversarial losses),使生成的图片在分布上更接近于目标图片;
- 循环一致性损失(cycle consistency losses),防止学习到的映射 G与F 相互矛盾。