[2012CVPRW]Gaze Estimation from Multimodal Kinect Data
Kenneth Alberto Funes Mora and Jean-Marc Odobez
Idiap Research Institute, CH-1920, Martigny, Switzerland
École Polytechnique Fédéral de Lausanne, CH-1015, Lausanne, Switzerland
{kfunes,odobez}@idiap.ch
评价:研究了头部运动不受限条件下的自由注视估计问题 free gaze estimation under unrestricted head motion。
针对问题:不同于以往的基于小平面屏幕a small planar screen的凝视方向估计方法,提出了一种基于三维空间的凝视方向估计方法。
实现的方法:
(i)在Kinect设备上,提出一个多模态的方法,即使在大的头部姿势也可以依靠深度感知获得健壮和精确的头部姿势跟踪,利用视觉上的数据,即从眼睛图像获得其余eye-in-head注视方向信息;
(ii)利用3D网格跟踪 (3D mesh tracking)的图像的校正方案,允许头部姿态自由情况下的进行对眼凝视方向估计;
(iii)给出了借助Kinect设备,收集真实数据的简单方法。
在三个用户身上的结果显示了方法的巨大潜力。
方法介绍
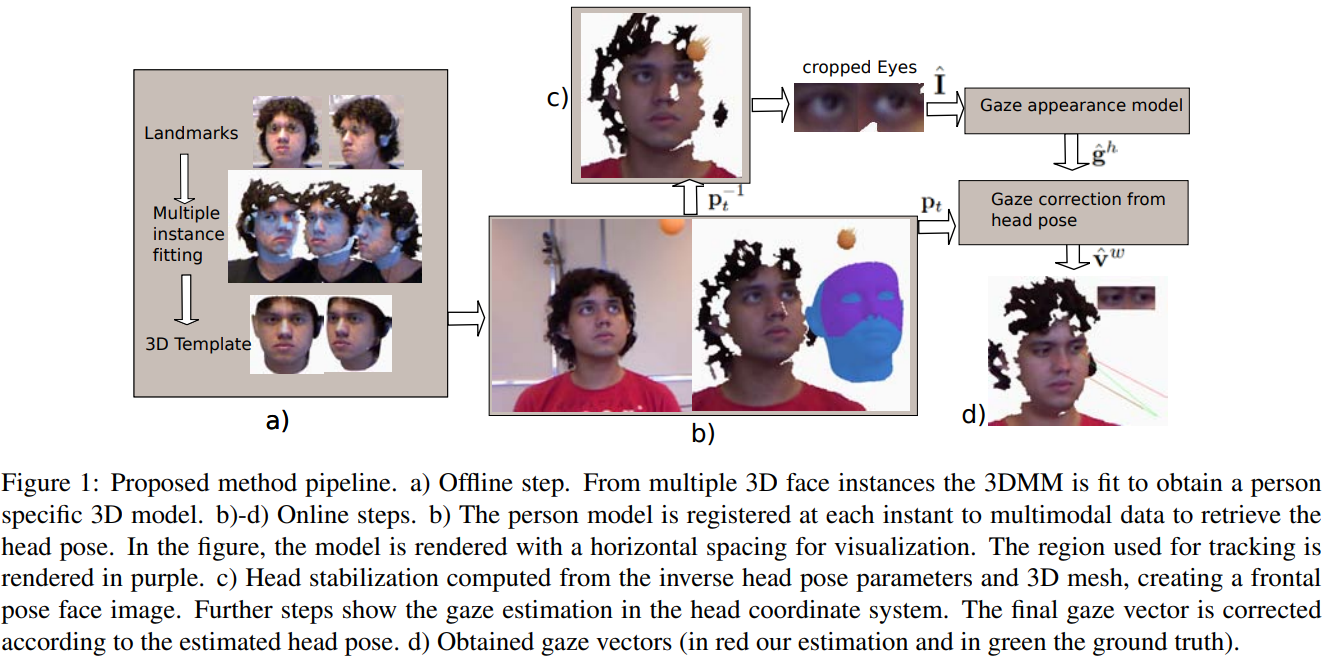
a)离线步:从多个3D人脸实例中,3DMM适合获得一个特定的人的3D模型。
b)- d)在线步骤
b)在每个时刻将人的模型叠合到多模态数据中,以检索头部姿态。在图中,模型是用水平间距呈现的(两个图片并排放置),以便于可视化。用于跟踪的区域呈现为紫色。(实际拍出来的深度图)
c)头部稳定Head stabilization 计算从逆头部姿态参数和3D网格中,创建一个正面姿态的脸图像。进一步的步骤显示了在头部坐标系下的注视估计。根据估计的头部姿态,对最终的注视向量进行校正。
可以看见图c相比于图b,图c中人脸做了正面化。
d)获得的注视向量(红色为估计值,绿色为真值)。
给定一个经过学习的特定于人的3D网格模型(章节3.1),该方法首先通过深度数据估计头部姿态,如章节3.2所述。对应a)离线步。
然后,使用估计的头部姿势和3D网格,我们将头部图像映射为一个正面姿势,并将结果图像裁剪到每只眼睛周围。
通过这种方法,我们可以从眼内图像(第3.4节)中估计注视向量,即在头部参考系统中估计眼睛注视。最后将注视方向转换回世界坐标系。
数据收集的缺点是继承了头部姿态跟踪器的误差,存在目标大小引入的不确定性,并且对眼中心进行了近似定义
Proposed method
Face model learning
我们决定依靠3D变形模型(3DMM)来生成特定于人的3D面部模板。这些模型(3DMM)使用一组小的系数跨越了大量的面部形状。
在我们的任务中,我们使用了Basel Face Model (BFM) [12],这是一个丰富的3DMM人脸模型,由一大群个体构建而成。
这是一个丰富的 3DMM。由一大群人组成。它有很高的网格密度(53490个顶点),包括脸、额颈和耳朵。3DMM形状可根据Eq. 1进行变形,其中$x$(模型实例)表示将三维顶点坐标${v_i}$叠加为列向量的集合,$\mu$为平均形状,$M$为形状基。模型参数为向量$α$。
所有head实例的拓扑都是固定的。这是使用3DMM生成人脸模型的主要优势,因为语义信息在拓扑中是预定义的,并且在个体之间保持。
为了生成针对特定人群的3D网格,我们将3DMM与深度数据进行了匹配。这是通过将形状变形受$α$约束的3DMM映射到Kinect的重构网格来实现的。为了解决这个问题,我们使用了[1]的方法,并最小化以下代价函数。
3DMM model

Head pose tracking
T. Weise, S. Bouaziz, H. Li, and M. Pauly. Realtime performance-based facial animation.ACM Trans. on Graphics (Proc. SIGGRAPH 2011), 30(4):1, July 2011
估计头部姿态的算法基于基于点对面约束和个性化模板的迭代最近点(ICP)算法。
它在给定帧初始化ICP时,从前一帧的推断值重新估计位姿参数。跟踪是通过逐帧重复这个过程获得的。在每个时刻,得到头部姿态参数$p_t = {R_t,t_t}$,即头部旋转和平移参数。
整个初始化过程是在视觉图像中使用一个标准的正面人脸检测器完成的。从深度数据中,检测包围框内的3D点集被用来初始化平移。假设头部朝向是正面的。ICP使用更小的个性化3D模型部分,以避免像[14]中那样由于非刚性变形而导致的不匹配。这一步骤如图1b所示。
Head stabilization
假设将Kinect数据表示为一个有纹理的3D网格,可以使用头部姿态参数的刚性逆变换来渲染场景。(正交矩阵?逆和转置是一样的)
眼睛的定位是在网格拓扑中预先定义的。使用这些信息在渲染的人脸图像中裁剪眼睛图像。这些眼睛图像将作为注视估计方法的输入。
相当于人脸做了正面化。
Eye-in-Head Gaze estimation
本文主要目标是估计在自由头部运动下的注视方向。然而,由于头部稳定的方法在此基础上,我们将该问题简化为一个正面头部姿态注视估计问题。因此,本文的任务是建立一个眼睛外观模型,从中可以进行估计注视。
假设有一组眼睛图像和注视向量$\{(I_i,g^h_i)\}$覆盖注视空间。(在第4节中,描述了一种收集这些样本的简单方法)。在头部参考系中,注视由角度$g^h_i = (\varphi_i,\theta_i)$参数化。其中$\theta$为注视仰角,$\varphi$为注视偏航角。
图像描述符$e_i$是通过将眼睛图像划分到一个网格$r×c$中计算出来的。在网格的每个bin $j= (r, c)$处,计算像素强度$S_j$的总和。然后,描述符是所有$S_j$的级联,并将其归一化,使$\sum_je_i^j =1$。因此,外观模型由集合组$\{(e_i,g^h_i)\}$成。使用$r= 3$,$c= 5$,遵循[3]的 方法。
[3]L. Feng, Y . Sugano, O. Takahiro, and Y . Sato. Inferring Human Gaze from Appearance via Adaptive Linear Regression.
InICCV: International Conference on Computer Vision, Barcelona, Spain
给定一个测试图像$I$,描述符$\hat{e}$,我们想推断它的注视方向$\hat{g}^h$。遵循了[3]中的方法。该方法的目标是通过对外观模型中样本的凸组合,得到最优重构测试图像的权重$w_i$。然后,使用这些权重将注视参数组合为
$\hat{g}^h= \sum_i w_i g^h_i$。

这种方法被称为自适应线性回归(ALR),它对$w_i$的解施加了稀疏性。它的成功依赖于${e_i}$足够稀疏。
相当于是把新给定的视线用已经训练的视线线性表示出来,使用特征描述子作为约束。使用L1损失可以有稀疏性。
3D gaze estimation
在经过姿势校正的头部正面参考中,估计出的注视方向$\hat{g}^h$可在世界坐标系中转换为注视方向$\hat{v}^w \in $$R^3$如下所示。
值得注意的是注视角参数$\hat{g}^h$可由指向$(\varphi,\theta)$方向的单位向量$\hat{v}^h \in $$R^3$表示。
因此,可以使用估计的头部姿态参数$p_t = \{R_t,t_t\}$来计算$\hat{v}^w = R_t \hat{v}^h$
在头部坐标系中,视线方向可以用三维单位向量表示,也可以用俯仰角和航偏角表示。计算世界坐标系中的视线方向,只需要做一次坐标转换即可。
Gaze ground-truth collection
Proposed setup and methodology
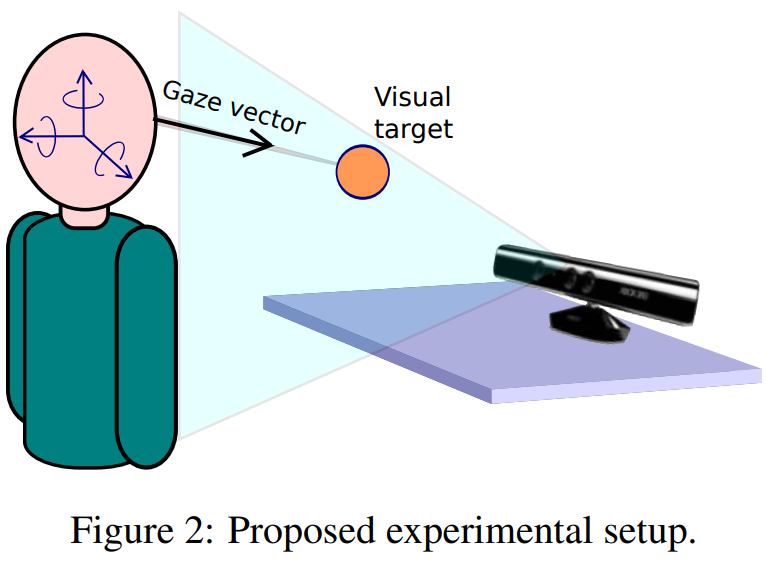
本文提出了一种从Kinect设备中收集地面真实数据的方法。在自由头部运动的情况下,将注视向量$v^w$定义为视轴,即从眼球中央凹指向视觉目标的向量(真实的视轴)。
图2显示了提议的设置。该系统包括一个微软Kinect设备和一个可识别的小物体。在我们的实验中,我们使用了一个4厘米的橙色球。当目标移动时,参与者被要求用眼睛跟随目标。考虑到注视目标在颜色和深度上都是有区别的(RGB,depth模态),可以可靠地跟踪它在每个时刻的3D位置。
利用头部姿态跟踪器,将视觉轴近似为从眼球中心到视觉目标估计位置的矢量。两只眼睛都这么做。该方法的缺点是继承了头部姿态跟踪器的误差,存在目标大小引入的不确定性,并且对眼中心进行了近似定义。然而,它显然是有优势的,因为它提供了一种简单的方法来收集大量的标记数据,并从中训练和测试我们的方法。
Recorded data
收集了3名参与者用眼睛跟踪目标的视频。对于每个人,使用3.1节中描述的方法学习个性化的头部3D头部模板。此外,为了将场景重构为一个有纹理的3D网格,首先使用校准Kinect传感器。
每段记录分为两部分。在第一部分中,参与者被要求在跟踪目标时保持头部正面的姿势。参与者没有必要保持一个严格的头部正面姿势,因为假设对于接近头部正面姿势的头部姿势Head stabilization是精确的。其目的是收集无遮挡的眼睛正面图像,建立基于外观的注视模型。
在记录的第二部分,参与者被要求在用眼睛跟踪视觉目标的同时进行头部自由旋转和平移。高度具有挑战性的头部姿势范围的偏航角度$\varphi$高达±60◦,俯仰值$\theta$高达±50◦。
对于外观模型的创建,使用了参与者头部正面姿势部分的前半部分。不取所有样本来建立外观模型,而是通过将俯仰值俯仰$\theta$的[−40◦,40◦]和航偏$\varphi$的[−50◦,50◦]区间划分为6$\theta$和7$\varphi$值,在注视空间中定义了一个由42个点组成的网格。
可以从记录中自动选择注视方向靠近网格点的样本。虽然固定头会话记录约为1.5分钟,但由于只需要少量样本,可以快速创建外观模型。图3a)显示了一个完整的记录过程(头部正面姿势)的计算的注视参数,而图3b)显示了从这个记录过程中获得的网格。

Experiments
论文中进行了一系列的实验来验证我们的方法。头部姿态跟踪器使用BIWI头部姿态数据库[2]进行验证,发现与他们报告的真值(这是使用类似的头部姿态跟踪器获得的)约1◦的偏差。
正如在第4节中提到的,凝视外观模型是由记录过程中前半部分的头部姿势创建的。使用后半部分record和所有的自由头部姿势的样本作为测试样本。
\1) 评价:贡献创新点。
\2) 针对问题:啥情况啥场景。
\3) 本文的目的:可以做到啥。
\4) 实现的方法:
\5) 方法简介
\6) 方法优化
\7) 方法总结‘
\8) 文章存在的问题
\9) 个人的思考
简要的评价,任务,方法的简要描述。关注文章的动机。