Cristina Palmero1,2crpalmec7@alumnes.ub.edu
1Dept. Mathematics and Informatics Universitat de Barcelona, Spain
Javier Selva1 javier.selva.castello@est.fib.upc.edu 2Computer Vision Center
Campus UAB, Bellaterra, Spain Mohammad Ali Bagheri3,4
mohammadali.bagheri@ucalgary.ca 3Dept. Electrical and Computer Eng.
University of Calgary , Canada Sergio Escalera1,2 sergio@maia.ub.es
4Dept. Engineering University of Larestan, Iran
评价:
提出了一个独立于受试者的、自由头部的三维凝视回归网络来利用图像序列的时间信息。每个帧的静态流使用多流CNN将人脸、眼睛区域和人脸地标以一种后期融合的方式组合。然后,将所有特征向量输入到多对一循环模块中,该模块预测最后一序列帧的注视向量。
多模态静态解决方案在广泛的头部姿态和注视方向上进行了评估,在EYEDIAP数据集上实现了14.6%的显著改进。
当包括时间模态时,进一步提高了4%。
我的感觉:用脸和眼睛作为输入,另一个模态是时间。
静态和时间版本分别提升了多少?
针对问题:凝视行为不是静态的。眼睛和头部的运动可以让我们把目光转向感兴趣的目标位置。已经证明,当人们看到一系列其他人移动眼睛的图像时,可以更好地预测人们的注视。然而,这种顺序信息是否能提高自动化方法的性能仍然是一个悬而未决的问题。
实现的方法:
提出了一种可循环使用的cnn网络结构,它结合了外观、形状和时间信息来进行3D凝视估计。
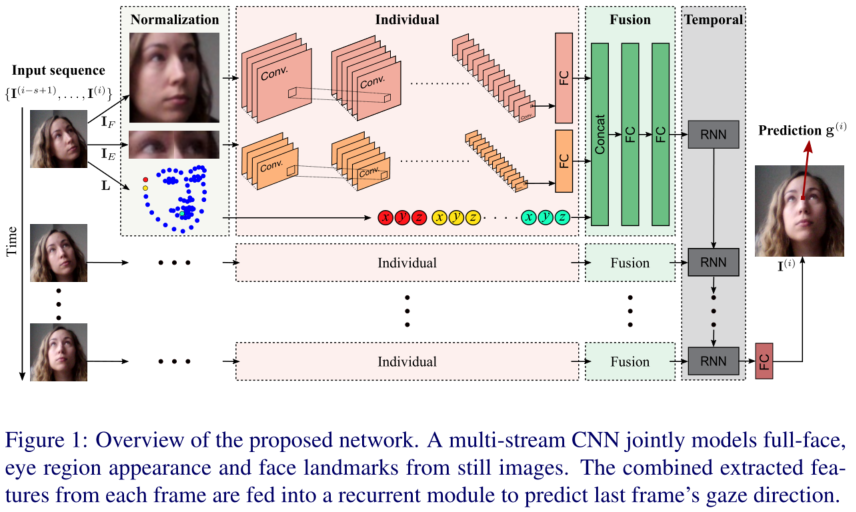
一个多流CNN对于来自静止图像的全脸,眼睛区域外观和人脸关键点联合建模。将从每一帧中提取的特征合并后输入循环模块,预测最后一帧的注视方向。
\5) 方法简介
\6) 方法优化
\7) 方法总结‘
\8) 文章存在的问题
\9) 个人的思考
Abstract
凝视行为是社会信号处理和人机交互中的重要非语言线索。在本文中,我们利用一个多模态递归卷积神经网络(CNN)来解决从远程摄像机中独立于人和头部姿态的3D凝视估计问题。我们提出将人脸、眼睛区域和人脸地标作为CNN中的单独流来估计静态图像中的凝视。然后,我们利用注视的动态特性,将序列中所有帧的特征输入多对一循环模块,该模块预测最后一帧的3D注视向量。我们的多模态静态解决方案在广泛的头部姿态和注视方向上进行了评估,在EYEDIAP数据集上实现了14.6%的显著改进,当包括时间模态时,进一步提高了4%。
Introduction
在非语言行为分析中,眼睛及其运动被认为是一个重要的线索,它参与了许多认知过程,反映了我们的内部状态。更具体地说,眼睛注视行为,作为人类视觉注意力的一个指标,已经被广泛研究来评估沟通技能[28]和识别可能的行为障碍[9]。因此,凝视估计已经成为计算机视觉的一条已确定的研究路线,是人机交互(human-computer interaction, HCI)和可用性研究的关键特征[12,20]。
最近的凝视估计研究集中在促进其在现实生活条件下的日常应用中使用,使用现成的远程RGB相机和消除个人校准[26]的需要。在这种情况下,基于外观的方法,即学习从图像到注视方向的映射,是首选方法。然而,他们需要大量的训练数据才能很好地概括野外环境,野外环境的特征是头部姿势、面部外观和光照条件的显著变化。近年来,有报道称cnn优于传统方法。然而,大多数现有的方法只在有限的人机交互任务中测试过,
另一方面,直到最近,大多数方法只使用静态眼区域外观作为输入。最先进的方法已经证明,使用脸部和更高分辨率的眼睛图像[16],甚至只是脸部本身[43],都能提高性能。事实上,整张脸的图像比眼睛能编码更多的信息,比如光照和头部姿势。然而,凝视行为不是静态的。眼睛和头部的运动可以让我们把目光转向感兴趣的目标位置。已经证明,当人们看到一系列其他人移动眼睛的图像时,可以更好地预测人们的注视。然而,这种顺序信息是否能提高自动化方法的性能仍然是一个悬而未决的问题。
在这项工作中,我们表明,多种线索的组合有利于注视估计任务。特别是,我们从静态图像中使用脸部、眼部区域和面部地标。由于人脸对齐是许多人脸图像分析方法中常见的预处理步骤,因此人脸地标模型无需任何成本就能对人脸的整体形状进行建模。此外,我们提出了一个独立于受试者的、自由头部的三维凝视回归网络来利用图像序列的时间信息。每个帧的静态流使用多流CNN以一种后期融合的方式组合。然后,将所有特征向量输入到多对一循环模块中,该模块预测最后一序列帧的注视向量。
总之,我们的贡献是双重的。首先,我们提出了一种可循环使用的cnn网络结构,它结合了外观、形状和时间信息来进行3D凝视估计。其次,我们在EYEDIAP数据集[7]上测试了我们的解决方案的静态和时间版本,在广泛的头部姿势和注视方向上,与基于外观的相关方法相比,显示出一致的性能改进。据我们所知,这是第一种基于第三人称远程相机的方法,它使用时间信息来完成这项任务。表1概述了与相关工作相比,我们的主要方法特点。模型和代码可在
Related work
凝视估计方法通常分为基于模型和基于外观的两类[5,10,15]。基于模型的方法使用眼睛的几何模型,通常需要高分辨率的图像或特定的人的校准阶段来估计个人的眼睛参数[22,33,34,37,41]。相比之下,基于外观的方法从强度图像或提取的眼睛特征到注视方向的直接映射,因此被可能适用于相对低分辨率图像和中距离场景。研究了不同的映射函数,如神经网络[2]、自适应线性回归(ALR)[19]、局部插值[32]、高斯过程[30,35]、随机森林[11,31]或k近邻[40]。基于外观的3D凝视估计方法的主要挑战是头部姿态、光照和主体不变性,而不需要用户特定的校准。为了处理这些问题,一些著作提出了补偿方法[18]和扭曲策略,这些方法综合了一个规范的、正面的面部视图[6,13,21]。基于综合分析的混合方法也被评价在[39]。
目前,数据驱动的方法被认为是基于人和头部姿态独立的基于外观的凝视估计的最新技术。因此,近年来引入了许多凝视估计数据集,这些数据集可以是受控的[29]或半受控的[8]设置,也可以是野外的[16,42],也可以是由合成数据组成的[31,38,40]。Zhanget al.[42]表明,CNN可以优于其他映射方法,使用多模态CNN学习从3D头部姿势和眼睛图像到3D注视方向的映射。Krafkaet al.[16]提出了一种用于二维注视估计的多流CNN,使用个体眼睛、全脸图像和脸网格作为输入。由于该方法仅限于2D屏幕映射,所以Zhanget al.[43]后来探索了仅使用全脸图像作为输入来估计3D注视方向的潜力。通过使用空间加权CNN,他们证明了他们的方法对由头部姿势和光照引起的面部外观变化比只使用眼睛的方法更稳健。虽然该方法是在野外评估的,但受试者仅与移动设备交互,因此限制了头部姿势的范围。Deng和Zhu[4]提出了一种两流CNN,从人脸图像中分离出头部姿态模型,从眼区图像中分离出眼球运动模型。然后使用注视转换层将两者聚合成三维注视方向。分解的目的是避免以往数据驱动方法的头相关过拟合。他们在野外用更大范围的头部姿势来评估他们的方法,获得了比以前基于眼睛的方法更好的性能。然而,他们并没有在公共标注的基准数据集上进行测试。
在本文中,我们提出了一个多流循环的CNN网络,用于一个中距离场景的人和头部姿态独立的3D凝视估计。与屏幕定向的方法相比,我们在更大范围的头部姿势和注视方向上评估它。与以前的方法相反,我们也依赖于时序数据中固有的时间信息。
Methodology
在本节中,对于静态图像和图像序列基于外观和形状线索的3D凝视回归方法。首先,我们引入数据模式 data modalities并阐明问题。然后,详细说明回归阶段之前的归一化过程。最后,我们解释了全局网络拓扑结构以及实现细节。系统架构的概述如图1所示。
Multi-modal 多模式的gaze regression
在相机坐标系中将注视方向表示为一个三维单位向量$\bold{g}=[g_x,g_y,g_z]^T$,眼球中心之间的中心点是它的原点。假设一个校准过的相机,一个已知的头部位置和方向,目标是从一个图像序列$\{I^{i}|I \in R^{W\times H \times 3}\}$估计为一个回归问题。
凝视一个特定的目标是通过眼睛和头部的高度协调运动来实现的。因此,注视的视向不仅受到眼睑孔内虹膜位置的影响,而且还受到人脸相对于相机的位置和方向的影响。这被称为沃拉斯顿效应[36],由于周围的面部线索,同一对眼睛可能看起来在看不同的方向。因此,有理由说,眼睛图像不足以估计注视方向。相反,与眼睛区域相比,整张脸的图像可以在更大的区域内编码头部姿势或特定光照的信息[16,43]。
纯外观方法的缺点是没有明确地考虑全局结构信息。在这个意义上,面部标志可以作为全局形状线索来编码空间关系和几何约束。目前最先进的人脸对齐方法足够健壮,可以处理大的外观变化,极端的头部姿态和遮挡,特别是当用于注视估计的数据集不包含这种变化时,这是非常有用的。面部地标主要与头部方向、眼睛位置、眼睑开度和眉毛运动有关,这些对我们的任务都是有价值的特征。
因此,在我们的方法中,我们联合建模外观和形状线索(见图1)。前者是由全脸图像,以及更高分辨率的眼睛图像来识别微妙的变化。由于处理大的头部姿势范围,一些眼睛图像可能不描绘整个眼睛,而是包含大部分背景或其他周围的面部部分。因此,与之前只使用一只眼睛图像的方法相反[31,42],我们使用由居中的左右眼睛的两个斑块组成的单一图像。最后,从68个地标模型中获取三维人脸地标来表示形状线索,表示为$L=\{(l_x,l_y,l_z)_c|{\forall}c \in [1,…,68]\}$ 。
在本研究中,我们还考虑了注视的动态成分。我们利用眼睛和头部运动的顺序信息,这样,给定连续帧的外观和形状特征,就有可能更好地预测当前帧的注视方向。
因此,一帧序列的3D凝视估计任务可以公式化为$g^{(i)} = f( I_F^{(i)},I_E^{(i)},L^{(i)})$,i表示为第i帧,f表示回归函数。
高分辨率眼睛图像🤔插值得来的?
Data normalization
在凝视回归之前,对三维空间和二维图像进行类似于[31]的归一化步骤。这样做是为了减少外观的可变性,并允许无论原始相机配置如何都可以应用凝视估计模型。
虚拟相机
$H \in R^{3X3}$是头部旋转矩阵,
$p = [p_x,p_y,p_z]\in R^3$是相对于原始CCS的参考人脸位置。标是找到转换矩阵$M=S*R$满足
a)通过旋转矩阵$R$,虚拟摄像机的X 轴和头部变得平行,
b)使用Z方向缩放矩阵 $S=diag(1,1,d_n/||p||)$虚拟摄像机从固定距离$d_n$查看参考位置。$R$计算为$a=\hat{p}\times H^Te_1$,$b=\hat{a} \times \hat{p}$,$R=[\hat{a},\hat{b},\hat{p}]$,$e_1$表示第一个正交基,$<\hat{.}>$表示单位向量。
p为拍摄的真实相机到参考点的直线。H的特征向量。
这一归一化转换为图像空间为大小$Wn×Hn$中心为$p$的裁剪图像补丁,其中头部滚动旋转已被移除。这是通过使用转换矩阵$W=C_0MC_n^{-1}$对输入图像$I$应用透视扭曲来完成的,其中$C_0$和$C_n$分别是原始和虚拟相机矩阵。
三维凝视向量也归一化为$g_n = Rg$,图像归一化后,视线可在2D空间中表示。因此,$g_n$转化为单位长度,可以被进一步转换成球坐标($\theta$,$\phi$)