[AAAI2022]PureGaze: Purifying Gaze Feature for Generalizable Gaze Estimation
Yihua Cheng1, Yiwei Bao1, Feng Lu1, 2*
1State Key Laboratory of VR Technology and Systems, School of CSE, Beihang University
2Peng Cheng Laboratory, Shenzhen, China
{yihuac, baoyiwei, lufeng}@buaa.edu.cn
提炼
解决问题:
解决了跨域估计问题。与常用的域自适应方法不同。
评价:
提出了一种域泛化方法,在不接触目标样本的情况下提高跨域性能。通过凝视特征净化实现了领域泛化。消除了与注视无关的因素,如光照和身份,以提高跨域性能。
设计了一个即插即用的自我对抗框架来净化凝视特征。该框架不仅增强了的baseline,而且直接和显著地增强了现有的注视估计方法。
方法只在源域进行训练,并在所有未知的目标域进行改进。该方法的核心思想是利用 self-adversarial framework框架来净化凝视特征。
出现跨域效果不好的原因:
内在的注视模式在所有领域都是相似的,但在与注视无关的因素(如照明和身份)中存在领域差异。这些因素通常是特定于领域的,并直接混合在捕获的图像中。深度融合使得这些因素在特征提取过程中难以消除。因此,经过训练的模型通常会学习凝视和这些因素的联合分布,即来源上的过拟合。
方法简介:
提出了一个即插即用的自我对抗框架。idea如下:
如图1所示,核心思想是净化凝视特征,即消除与凝视无关的因素,如照明和身份。纯化后的特征比原始特征更具通用性,自然会带来跨域性能的改善。
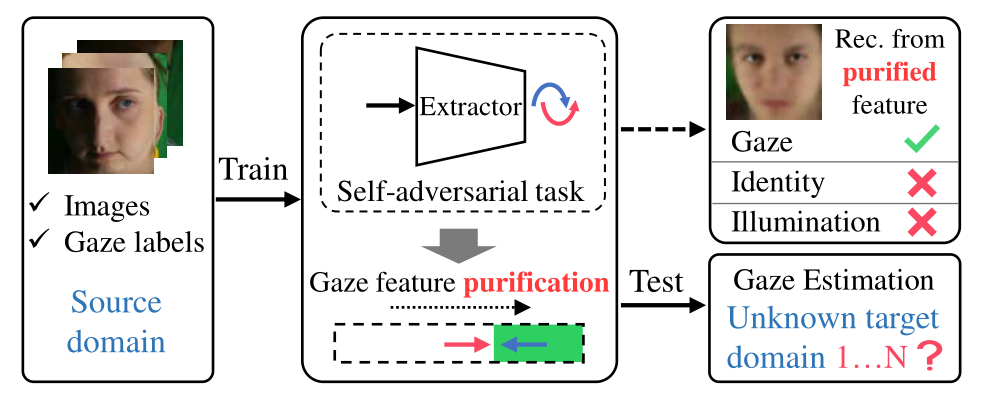
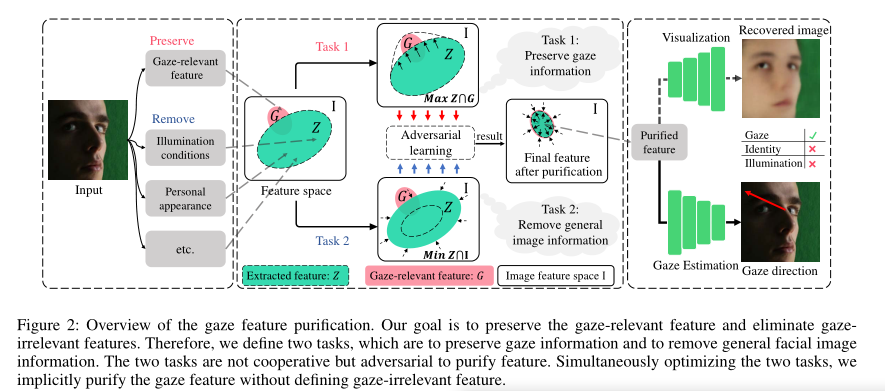
如图2所示,该框架包含两个任务,即保留注视信息和移除一般面部图像信息。在优化这两个任务的同时,我们隐式地净化了凝视特征,而没有定义与凝视无关的特征。事实上,定义所有与凝视无关的特征也是非常重要的。
如图3所示,这两个任务分别近似为凝视估计任务和对抗性重建任务。最终的PureGaze同时执行这两项任务,以净化凝视特征。PureGaze包含一个即插即用SA模块,可用于直接显著增强现有的凝视估计方法。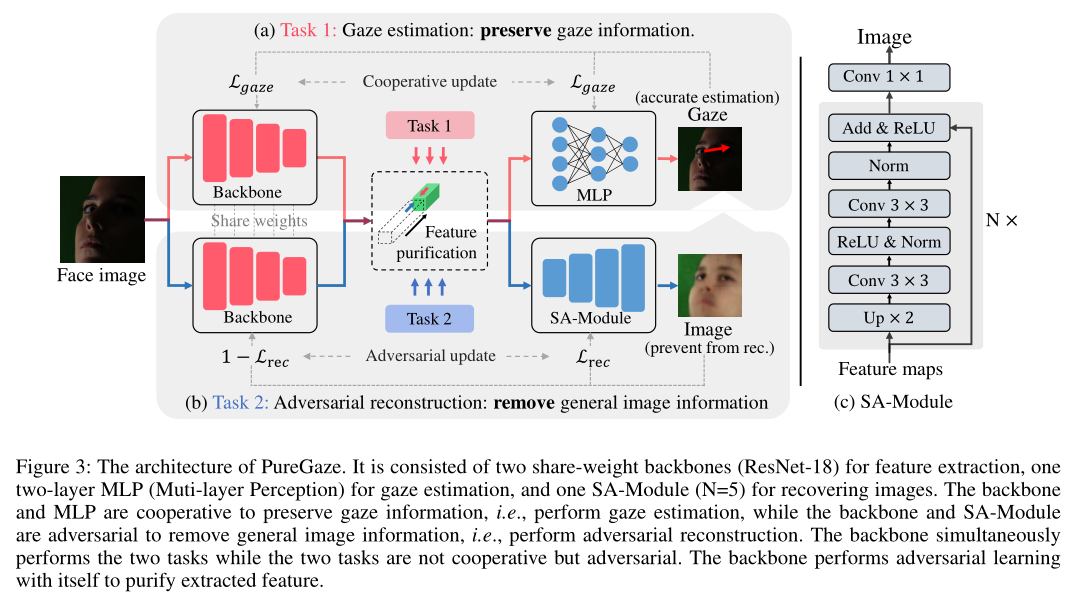
图3:PureGaze的架构。它由两个用于特征提取的共享权重主干(ResNet-18)、一个用于凝视估计的两层MLP(多层感知)和一个用于恢复图像的SA模块(N=5)组成。backone和MLP协同保存凝视信息,即执行凝视估计,而backbone和SA模块对抗性移除一般图像信息,即执行对抗性重建。主干同时执行这两项任务,而这两项任务不是合作的,而是对抗的。主干自身执行对抗性学习,以净化提取的特征。
这项工作的贡献有三个方面:
提出了一个即插即用的凝视估计方法领域泛化框架。它在不知道目标数据集或接触任何新样本的情况下提高了跨数据集的性能。它是凝视估计中的第一个领域泛化框架。
设计了一个自我对抗框架来净化凝视特征,消除了与凝视无关的因素,如照明和身份。如实验所示,通过可视化很容易解释纯化过程。
方法在许多基准测试中都达到了最先进的性能。即插即用模块还显著增强了现有的视线估计方法。
实验部分
训练:使用Gaze360(Kellnhofer et al.2019)和ETH XGaze(Zhang et al.2020)作为训练集,因为它们有大量的受试者、不同的注视范围和头部姿势。
测试:在两个流行的数据集中测试了我们的模型,它们是MPIIGaze(Zhang等人,2017年)和Eyedip(Funes Mora,Monay和Odobez,2014年)。总共执行了四个跨数据集任务,并将它们表示为E(ETH-XGaze)→M(mpiGaze),E→D(Eyedip),G(Gaze360)→M、 G→D。
与原始特征相比,净化后的特征包含的身份信息更少。每个受试者重建的面部外观大致相同
-净化后的特征包含较少的照明因子。此外,有趣的是,我们的方法还可以从弱光图像中准确地恢复明亮的注视区域。这意味着我们的方法能够有效地提取破黑函下的凝视信息
-除了照明和身份因素外,我们的方法还消除了其他与凝视无关的特征,如图5(a)中的头枕。
请注意,我们的方法没有指定消除的因素。PureGaze会自动净化学习到的。这是我们的方法的一个优点,因为手动列出所有与凝视无关的特征并非易事
Data Preparing
我们遵循(Cheng等人,2021年)准备数据集。
Gaze360:Gaze360(Kellnhofer et al.2019)数据集包含238名受试者共172K张图像。Gaze360中的大多数图像只捕捉到了主体的背面。这些图像不适用于基于外观的方法。因此,我们首先用一个简单的规则清理数据集。我们根据提供的人脸检测注释删除没有人脸检测结果的图像。
ETHXGaze:ETHXGaze(Zhang等人,2020年)共包含1个。110名受试者拍摄了100万张照片。它提供了一个包含80个主题的训练集。我们将5名受试者分成5组进行验证,其他受试者用于训练。
MPiiGaze(Zhang et al.2017)是根据标准方案编制的。我们总共收集了15名受试者的45K图像。
Eyedip(Funes Mora、Monay和Odobez 2014)提供了16个subject的94个视频片段。我们按照(Zhang et al.2017;Cheng et al.2020a)中的常见步骤准备数据。具体来说,我们选择屏幕目标会话的VGA视频,每15帧采样一幅图像。我们还截断数据,以确保每个subject的图像数量相同。
数据校正。执行数据校正以简化注视估计任务。我们按照(Sugano、Matsushita和Sato 2014)处理MPIIGaze,并按照(Zhang、Sugano和Bulling2018)处理Eyediap。ETH XGaze在出版前已被纠正。Gaze360会调整他们的注视方向,以消除相机姿势造成的效果。我们直接使用他们提供的数据。
Comparison Methods
Baseline:我们在PureGaze中删除SA模块。新网络被表示为基线。显然,PureGaze和Baseline之间的性能差异是由SA模块造成的。我们还将基线提取的特征表示为原始特征original feature,将PureGaze提取的特征表示为纯化特征 purified feature。
Gaze estimation methods:我们将我们的方法与四种方法进行了比较,分别是Full Face(张等人2017年)、RT Gene(Fischer、Jin Chang和Demiris 2018年)、 Dilated(Chen和Shi 2019年)和CA Net(Cheng等人2020a)。这些方法在数据集评估中都表现良好。我们使用Pytorch实现了 Full-Face and Dilated-Net,并使用了其他两种方法的官方代码。
Domain adaption methods:
我们还将我们的方法与域自适应方法进行了比较,以供参考。事实上,将我们的方法与域自适应方法进行比较是不公平的,因为这些方法需要目标样本。
对抗性学习(ADL)(Kellnhofer et al.2019)在凝视估计中被证明是有用的,并且与我们的方法具有相似的特征。我们使用ADL进行主要比较。我们还将该方法修改为ADL∗, 只使用鉴别器来区分源域中的个人特征personal feature。ADL∗ 我们的方法不需要目标sample。此外,我们还直接报告了(Liu等人,2021年)中其他域自适应方法的性能,以供参考。
Performance Comparison with SOTA Methods
我们首先在四个跨数据集任务中进行实验。结果显示在table3中。
请注意,由于ETHXGaze不能始终提供可靠的眼部图像,因此Dilated-Net, CA-Net and RT-Gene不适用于ETHXGaze。
此外,ETH XGaze数据集使用现成的ResNet50作为基线。我们遵循协议,在我们的方法中替换backbone,在 XGaze中用ResNet50替换ADL。
Comparison with typical gaze estimation methods:
table3的第二行。3显示了我们的方法和凝视估计方法之间的比较。我们的方法和比较的方法都是在源域上进行训练,并在目标域上进行评估。显然,现有的视线估计方法在跨数据集评估中往往表现不佳。这是因为这些方法很容易在源域中过度拟合。相比之下,由于架构简单,我们的基线在所有任务中都具有良好的性能。PureGaze进一步提高了基线的性能,并在所有任务中实现了最先进的性能。
我们提供了不同类型方法之间的苹果对苹果的比较。我们选择三种具有相同主干的方法进行公平比较。在相同条件下,PureGaze(域泛化方法)比基线(典型的注视估计方法)获得更好的性能。这是我们方法的一个优点。ADL(domain adaption methods,域自适应方法)也比基线具有更好的性能,同时需要时间进行设置和目标样本的自适应。
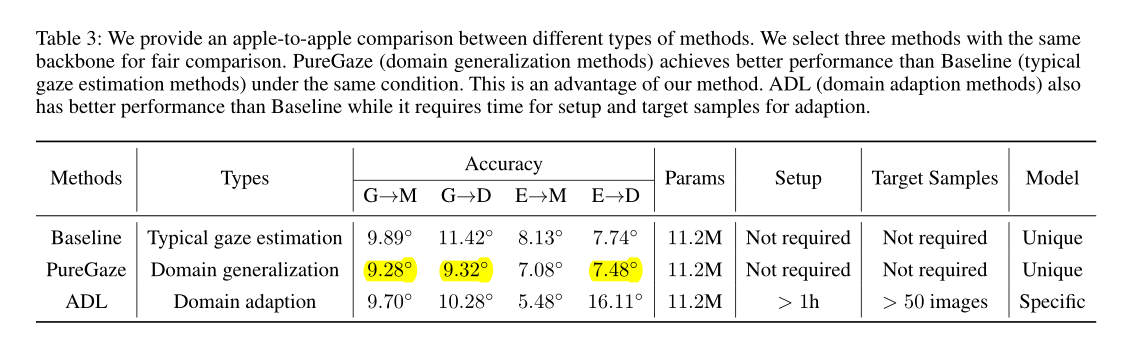
Comparison with domain adaption methods:
表1的第三行显示了域自适应方法的性能。ADL与PureGaze具有相同的主干。它在三个任务中提高了性能,并且失败了E→D.在比较的方法中,它的性能也是最好的E→M.与ADL相比,PureGaze在三项没有target samples的任务中都优于ADL。这证明了我们方法的有效性。
另一方面,我们评估了ADL的性能∗ 并在表1的第二行显示结果。没有目标样本,ADL∗不能总是带来性能改进。这是因为很难在所有未知领域提高性能,也证明了我们方法的价值。PureGaze超越ADL∗在所有任务中。
表1还显示了其他域自适应方法的性能。PureGaze在这些没有域自适应的域自适应方法中显示出了竞争性的结果。此外,我们还提供了PureGaze的一个简单应用程序,我们从目标域中每人采样5张图像,以微调PureGaze。经过微调的PureGaze通过快速校准/自适应进一步提高了性能。更有价值的是,我们观察到微调后的PureGaze也比微调后的基线具有更好的性能。这证明PureGaze学习了更好的特征表示。
Plug Existing Gaze Estimation Methods
我们还将我们的自我对抗框架应用于FullFace(Zhang等人2017)和CA Net(Cheng等人2020a)。我们将他们最终的面部特征图输入到SA模块中,只需添加两个损失函数Lrec 和Ladv。
结果显示在tab2.令人惊讶的是,CA Net在 G→M中的表现最差→而CA-Net-SA在 G→M.中的性能最好→除此之外,它在 G→D中也提高了近70%.在所有任务中, Full-FaceSA也比 Full-Face表现出更好的表现。该实验与典型的注视估计方法进行了更公平的比较,并证明了我们的自我对抗框架的即插即用特性。注意,我们的框架不需要额外的推理参数和训练图像。这是我们方法的一个关键优势。
Ablation Study of Two Loss Function
自我对抗框架提供了PureGaze的主要架构,尽管它很粗糙。我们还提出了两个损耗函数(LP损耗和TA损耗)来增强PureGaze。这两个损失函数都有超参数,即LP损失中的方差σ2和TA损失的阈值K。在本节中,我们对不同的超参数进行了实验。
如图4(a)和图4(b)所示,我们为σ2设置了四个值,分别为10、20、30和40,并在没有损失的情况下评估性能。我们在这两幅图的顶部展示了生成的注意力地图。至于TALoss,我们设置了四个值fork,分别为0,0。25,0. 5和0。75.k=0也意味着我们消除了TA损失。结果如图4(c)和图4(d)所示。很明显,这两个损失函数都带来了性能改进。当k=0时。当σ2=20时,PureGaze的性能最好。
Visualize Extracted Feature via Reconstruction
为了验证凝视特征净化的关键思想,我们将净化后的特征可视化,以便进一步理解。我们提供,用于比较的纯化特征和原始特征的重建结果。我们直接显示SAModule的输出,以可视化纯化的特征。我们冻结预训练模型的参数,并简单地训练一个样本模块,从原始特征重建图像。
根据图5所示的可视化结果,我们很容易得出以下结论:
-与原始特征相比,净化后的特征包含的身份信息更少。每个受试者重建的面部外观大致相同
-净化后的特征包含较少的照明因子。此外,有趣的是,我们的方法还可以从弱光图像中准确地恢复明亮的注视区域。这意味着我们的方法能够有效地提取黑暗区域下的凝视信息。
-除了照明和身份因素外,我们的方法还消除了其他与凝视无关的特征,如图5(a)中的头枕。
Discussion
1)领域泛化。凝视估计方法在新环境下测试时通常会有较大的性能下降。该特性限制了视线估计的应用。在本文中,我们创新了一个解决跨领域问题的新方向。与领域自适应(DA)方法相比,领域泛化(DG)方法更加灵活,例如,DA方法的设置通常比较花时间,而DG方法可以直接应用于新领域。但作为一种权衡,由于缺乏目标域信息,DG方法的性能通常比DA方法差。研究人员应该考虑灵活性和准确性之间的权衡。
2)自我对抗框架。我们提出了一个自我对抗的学习框架。净化后的功能在不接触目标样本的情况下提高了跨域性能。事实上,我们的框架也可以被认为是一种 zero-shot cross-domain method零拍跨域方法,因为我们不需要目标域中的样本。zero-shot 零拍机制是基于观察设计的,凝视模式在所有领域都是相似的,而一些与凝视无关的因素通常是特定领域的,会导致性能下降。我们的方法消除了一些与注视无关的特征,自然地提高了跨域性能。然而,与DA方法一样,我们的方法在源域中是不稳定的。我们的方法略微改变了源域的性能(±0.2)◦). 这是因为与PureGaze相比,过拟合模型可以在源域中获得更好的性能。学习更广义的模型是我们框架的未来方向。
Conclusion
在本文中,我们创新了一个新的方向来解决视线估计中的交叉数据集问题。我们提出了一个即插即用的领域泛化框架。该框架在不接触未知目标域的情况下,净化了凝视特性,提高了未知目标域的性能。实验表明,我们的方法在典型的注视估计方法中取得了最先进的性能,并且与领域自适应方法相比具有竞争力。
Additional Experiments
Comparison between Different Types of Methods
我们的方法是一种领域泛化方法。在本节中,我们进一步对我们的方法、典型的注视估计方法和域自适应方法进行了苹果对苹果的比较。我们选择基线作为典型注视估计方法的代表,ADL(Kellnhofer et al.2019)作为域适应方法的代表。这三种方法具有相同的主干,并提供了公平的比较。
结果显示在table3.PureGaze、基线和ADL的参数数量相同。这是因为PureGaze和ADL都是即插即用的。这两种方法学习更通用的特征表示,而不是改变网络结构以提高跨域性能。与基线相比,PureGaze在相同条件下获得了更好的性能。这是我们方法的一个优点。
ADL在降低灵活性的同时,也取得了比基线更好的性能。ADL需要耗时的设置和一些用于域自适应的目标样本。尽管最近的DomainAdaptionMethods不需要样本,但这些用户不友好的需求限制了视线估计方法的应用。另一方面,ADL学习每个领域的特定模型。相反,PureGaze为所有领域学习一种独特的模型。PureGaze无法大幅度提高特定领域的性能,例如,使用已知的特定领域信息来校准特定模型。这是我们方法的局限性。
Quantitative Evaluation in Illumination
特征重建实验表明,该方法能够从提取的特征中去除光照因子。在本节中,我们提供了不同照明强度下的性能改善分布,以便进行定量分析。我们在ETH XGaze中训练模型,并在MpiiiGaze中测试其丰富的光照变化。我们首先根据图像的平均强度将图像分为51个簇。然后我们移除少于7张图像的聚类,并计算平均精度。
与图7中的基线相比,我们展示了PureGaze的性能改进。有趣的是,我们的方法提高了在极端光照条件下的性能。这是因为我们的方法试图从提取的特征中去除与凝视无关的照明信息,因此比基线更具鲁棒性,尤其是在极端照明条件下。这些结果证明了纯化特征的优势。
abstarct
注视估计方法从面部特征中学习眼睛注视。然而,在人脸图像中的丰富信息中,真实的凝视相关特征只对应于眼睛区域的细微变化,而其他与凝视无关的特征,如照明、个人外观甚至面部表情,可能会以意想不到的方式影响学习。这是现有方法在跨域/数据集评估中表现出显著性能下降的一个主要原因。在本文中,我们解决了跨域估计问题。与常用的域自适应方法不同,我们提出了一种域泛化方法,在不接触目标样本的情况下提高跨域性能。通过凝视特征净化实现了领域泛化。我们消除了与注视无关的因素,如光照和身份,以提高跨域性能。我们设计了一个即插即用的自我对抗框架来净化凝视特征。该框架不仅增强了我们的基线,而且直接和显著地增强了现有的注视估计方法。据我们所知,我们是第一个提出凝视估计领域泛化方法的人。我们的方法不仅在典型的注视估计方法中取得了最先进的性能,而且在域自适应方法中也取得了有竞争力的结果
introduction
在本文中,我们创新了一个新的方向来解决这个问题。我们提出了一种改进跨域性能的域泛化方法。我们的方法不需要在目标域中使用任何图像或标签,而是针对任何“看不见”的目标域在源域中学习一个通用模型。我们注意到内在的注视模式在所有领域都是相似的,但在与注视无关的因素(如照明和身份)中存在领域差异。这些因素通常是特定于领域的,并直接混合在捕获的图像中。深度融合使得这些因素在特征提取过程中难以消除。因此,经过训练的模型通常会学习凝视和这些因素的联合分布,即来源上的过度匹配,自然也无法在目标领域表现出色。