由于图片拍摄时候外界环境,比如光线变化等会造成图片”风格”的不同,不同风格的同一张人脸经过landmark detector 可能会获得不同的地标,这并不是由于人脸结构本身造成。对于此问题的研究目前有两篇具有代表性的文章,主要思路都是通过数据增强,对图片进行某种风格变换,再去训练landmark detector,使得检测器对于风格变化具有鲁棒性。从而提高总体landmark检测准确度。
[2018CVPR]Style Aggregated Network for Facial Landmark Detection
Xuanyi Dong1, Yan Yan1, Wanli Ouyang2, Yi Yang1∗
1University of Technology Sydney,2The University of Sydney
{xuanyi.dong,yan.yan-3}@student.uts.edu.au;
wanli.ouyang@sydney.edu.au; yi.yang@uts.edu.au
评价:提出了一种对图像风格差异不敏感的风格聚合网络(style - aggregation Network, SAN)人脸地标检测方法。在face landmark detection领域第一个明确了图像风格变化问题造成可能会带来检测失误。
针对问题:不同图像风格差异较大的问题。除了人脸本身的方差外,图像风格的内在方差,如灰度与彩色图像、亮与暗、强烈与暗淡等。landmark检测器对于不同风格的同一张人脸图片有不同的输出。例:三张图片内容完全相同。唯一不同的是形象风格。使用训练好的面部标志检测器来定位面部标志。zoom部分显示不同风格图像上相同面部标志的预测位置之间的偏差。
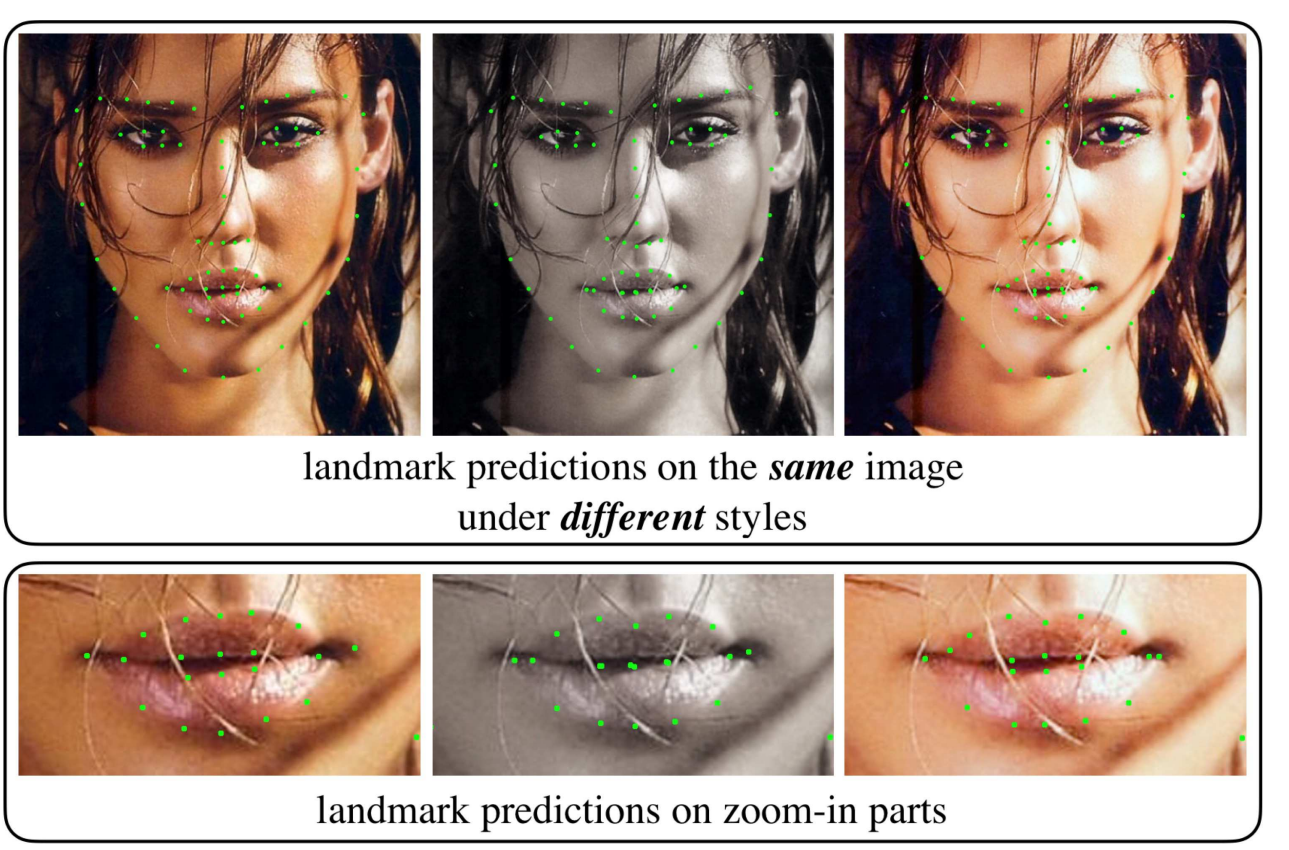
本文的目的:提高对图像风格的大方差的鲁棒性。
实现的方法:
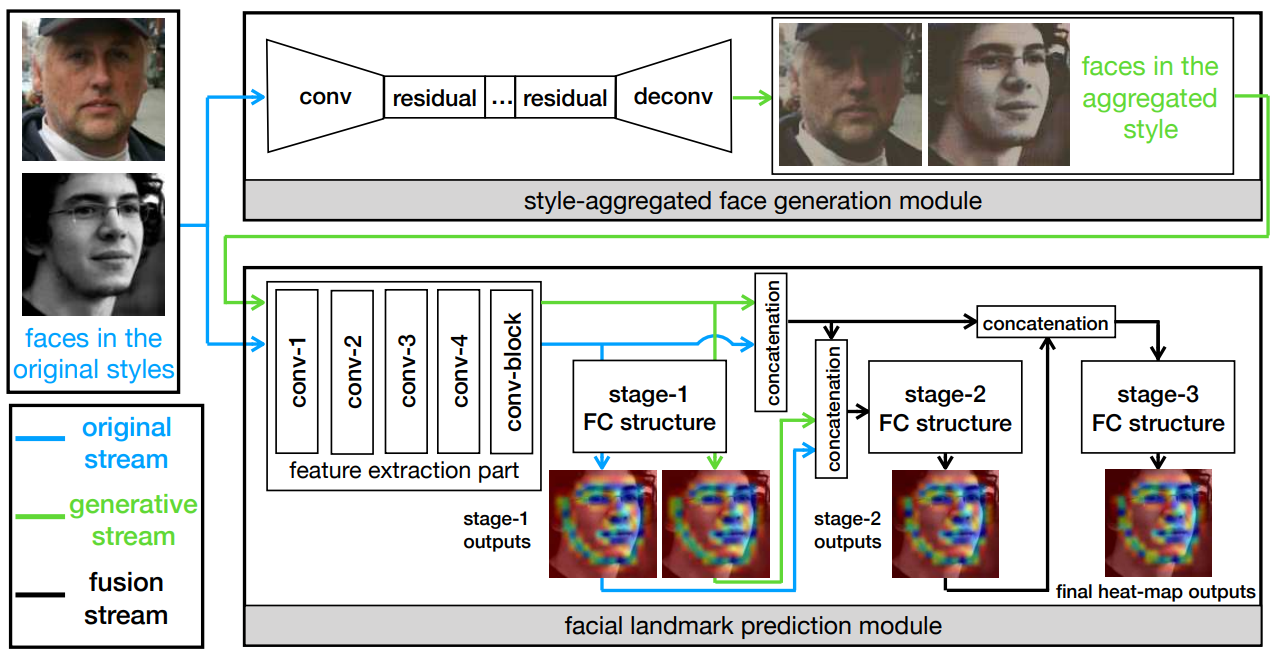
SAN架构概述。网络由两部分组成。第一个是样式聚合的脸生成模块,该模块将输入图像转换成不同的样式,然后将它们组合成样式聚合的脸。
二是人脸地标预测模块。该模块将原始图像和样式聚合图像作为输入,得到两个互补的特征,然后将两个特征进行融合,级联生成热图预测。“fc”意味着fully-convolution。
5.方法简介
数据增强(风格变化):通过将300-W和AFLW转换成不同的风格,发布了两个新的人脸标志物检测数据集:300W-Styles(≈12000 images)和AFLW- styles(≈80000 images)。
通过生成式对抗模块将原始人脸图像转换为风格聚合图像,使用风格聚合图像使得人脸图像对环境变化更具鲁棒性。
风格互补训练:将原始人脸图像与风格聚合的人脸图像作为双流输入landmark 检测器,二流输入可以互补。
假如测试阶段移除gan呢,相当于多模态训练,单模态测试?
在基准数据集AFLW方法表现良好。代码可在GitHub上公开获取:https://github.com/D-X-Y/SAN
6.个人的思考
相当于做了数据增强,增加了数据量。
[2019ICCV]Aggregation via Separation: Boosting Facial Landmark Detector with Semi-Supervised Style Translation
Shengju Qian1, Keqiang Sun2, Wayne Wu2,3, Chen Qian3, Jiaya Jia1,4
1The Chinese University of Hong Kong2Tsinghua University
3SenseTime Research4Y ouTu Lab, Tencent
{sjqian, leojia}@cse.cuhk.edu.hk, skq17@mails.tsinghua.edu.cn,{wuwenyan, qianchen}@sensetime.com
评价:
针对问题:鉴于任何人脸图像都可以被分解成光线、纹理和图像环境的风格空间,以及一个风格不变的结构空间,本文的关键想法是利用每个个体的风格和形状空间。[2018CVPR]Style Aggregated Network for Facial Landmark Detection中显式地研究了图像风格带来的畸变现象。
思路:
在实践中,图像内容是指对象、语义和边缘特征,而风格可以是颜色和纹理。
基于人脸地标检测的目的,即通过过滤不受约束的“风格”,回归“人脸内容”,即人脸几何的主成分。定义“style”是指的是图像背景、光线、质量、是否存在眼镜等阻碍探测器识别人脸几何形状的因素。
实现的方法:
利用风格迁移和解纠缠表征学习disentangled representation learning来处理人脸对齐问题,因为风格迁移的目的是在保留内容的同时改变风格。在不使用额外知识的情况下,增加人脸地标检测的训练。
方法简介:
a. 不是直接生成图像来做数据增强,而是首先将人脸图像映射到结构和风格的空间中。
b. 为了保证这两个空间的解纠缠,设计了一个条件变分自编码器模型,该模型将Kullback-Leiber (KL)散度损失和skip连接分别用于风格和结构的紧凑表示。通过分解这些特征,在现有的面部几何图形之间执行视觉风格转换。根据现有的人脸结构,将戴眼镜、质量较差、在模糊或强光下的人脸进行相应的风格,用于进一步训练人脸地标探测器,形成一个较为通用和健壮的人脸几何识别系统。
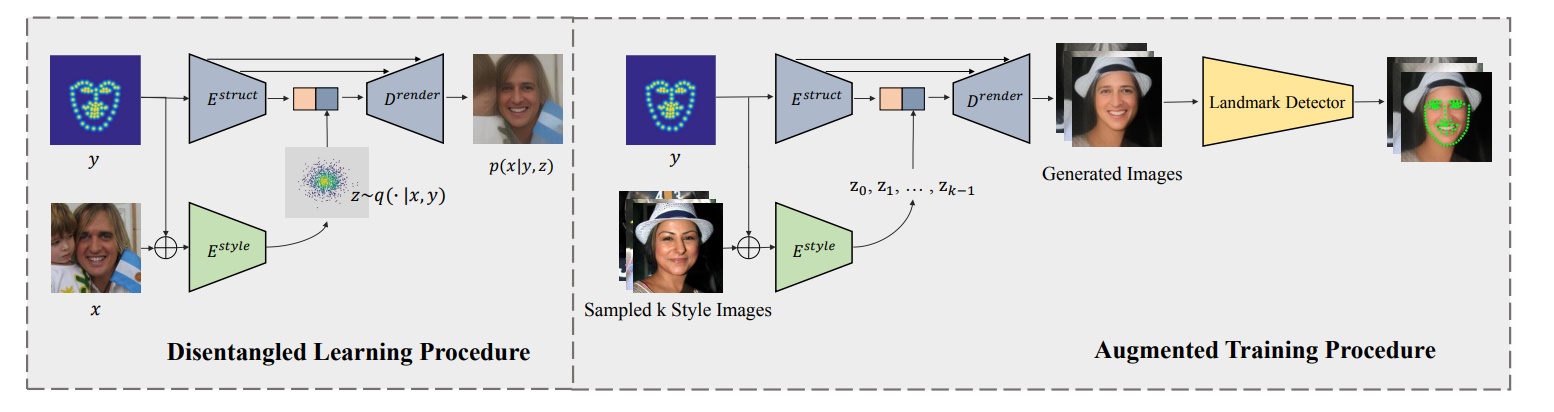
框架由两部分组成。一个是学习面部外观和结构的解离化表示,而另一个可以是任何面部标志检测器。
在第一阶段,提出了条件变化自动编码器,用于学习风格和结构之间的分离表示。
在第二阶段,在从其他人脸转换到风格后,带有结构的“风格化”图像可用于提高训练性能和风格不变检测器。
个人的思考
与第一篇文章中类似,相当于做了数据增强,增加了数据量。不同的是不是显示地改变光线或是rgb图转换成灰度,而是隐式地对于风格特征和结构特征进行了分离,在把一张图片风格迁移到其他风格。
实验效果


上面两张图 给出了在batch_size=8的情况下,第75个epoch和1000000个 epoch数据增强 的效果。
最上面第一行是第一列各个图像地关键点,也就是人脸地结构特征。在第二行到第九行中,第一列为原始图像,之后地第二列到第九列为各个原始图像保持原始landmark结构的情况下,生成的具有风格迁移地人脸。